Thank you to Barnabé Monnot, Brendan Farmer, Data Always, Elijah Fox, Hasu, Josh Bowen, Justin Drake, Lily Johnson, Luca Donno, Mert Mumtaz, Mike Neuder, mteam, Patrick O’Grady, Sacha Yves Saint-Leger, Vishesh, Yuki Yuminaga, and Zano Sherwani for valuable input, review, and related discussions.
The views expressed in this post are solely my own, and do not necessarily reflect those of the reviewers. If there are any technical inaccuracies, that’s because lower-case r researcher = blogger, sorry.
Introduction
This post analyzes the following
- Asynchronous execution – Why high-performance integrated blockchains (e.g., Solana and Monad) will decouple execution from consensus over ordering (sequencing).
- Lazy sequencing – How they will mirror the design of a lazy sequencer (e.g., Astria).
- Preconfirmations – Preconfs on Ethereum L1 and based rollups.
- Based vs. non-based – Comparing based rollups + preconfs vs. non-based rollups + base layer fallback.
- Universal synchronous composability – Via atomic inclusion (from shared sequencers) + cryptographic safety (e.g., AggLayer and/or real-time proving).
- Fast based rollups – Based rollups should just have a fast base layer.
- Timing games – Time is money, and how that underlies the divergent endgames between Solana vs. Ethereum.
- Decentralization for censorship resistance – How attester-proposer separation via execution auctions may preservce decentralized validators that can enforce censorship resistance with inclusion lists.
Lastly, and most importantly, we’ll see why we’re all building the same goddamn thing so maybe we should just…
Lesson 1 of building in crypto pic.twitter.com/YZONjsOqsm
— Eshita (@eshita) May 15, 2024
Optimizing State Machine Replication (SMR)
We’ll build up from the basics to see that the endgame for high-performance blockchains (e.g., Solana, Monad, HyperSDK) approaches that of a lazy sequencer (e.g., Astria). We’ll come full circle later to compare them vs. Ethereum based rollups + preconfs.
Sequencing vs. Execution
Blockchains are replicated state machines. Decentralized nodes each hold and update their own copy of the system’s state. To progress the chain, nodes run the state transition function (STF) over the current state + new inputs (e.g., new transactions). This produces the new state.
We will use the following terms throughout this section:
- Syntactically valid – Transaction is well-formed with a proper transaction structure and signature.
- Semantically valid – Transaction performs a valid state transition (e.g., pays the requisite fees).
- Sequence – Determine the ordering and inclusion of data.
- Execute – Interpret and act on the data in accordance with the STF.
- Build – Create a block (or partial block chunk/shred) from transactions stored locally.
- Verify – Perform the required syntactic and/or semantic verification of a block (or partial block chunk/shred).
- Replicate – Disseminate a block (or partial block chunk/shred) to other validators.
Let’s zoom in on sequencing and execution, because these are the core subtasks needed to compute the state of the chain:
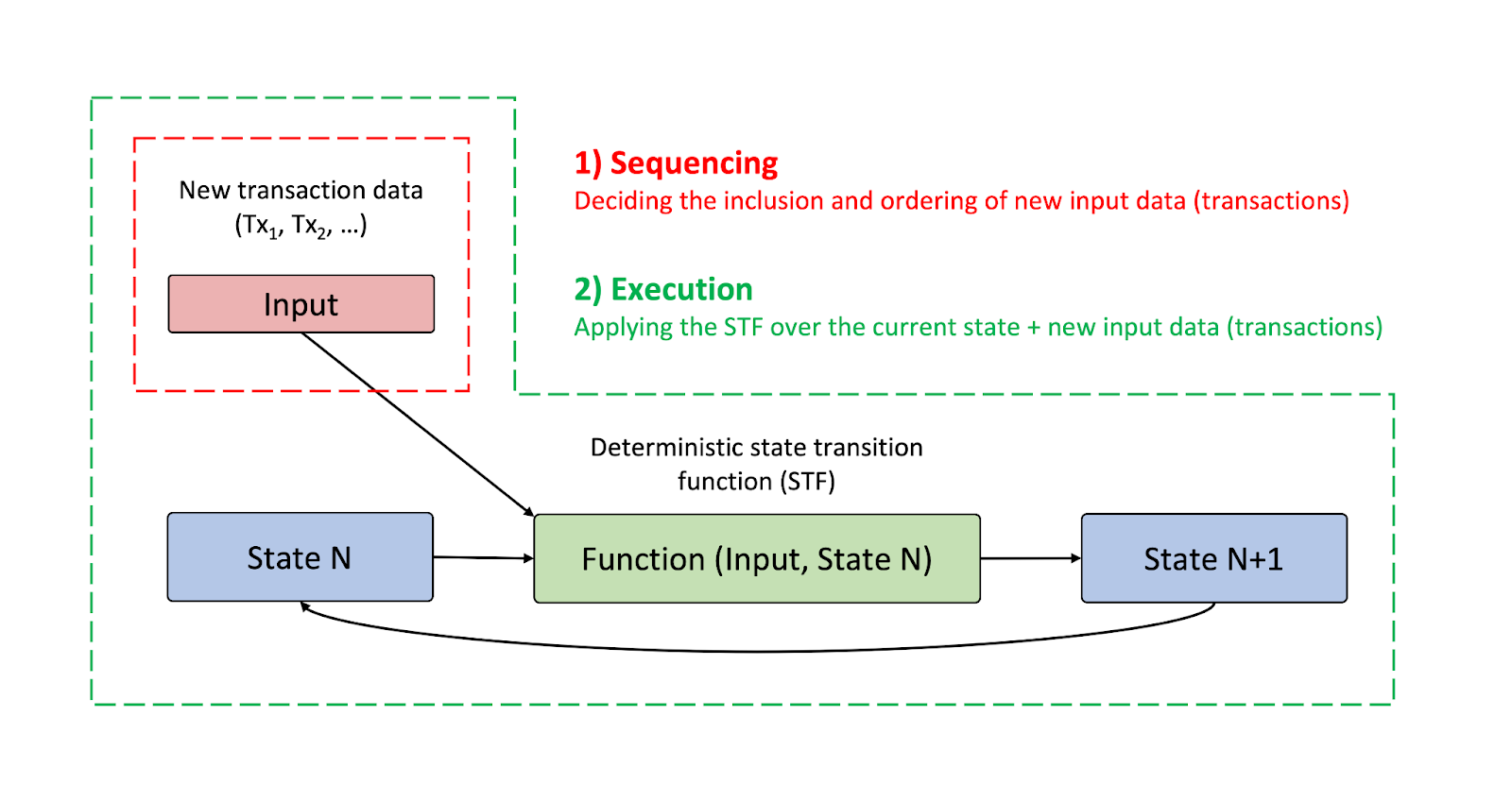
Additionally, nodes verify and replicate the data across the network. Nodes reach consensus to keep a consistent view of the chain.
However, different chain architectures diverge meaningfully in who is responsible for these tasks and when they do so (e.g., block building and verification may or may not include execution). The end-to-end time of the full state machine replication (SMR) loop dictates the lower bounds on system latency. Different constructions can yield highly variable times, so an SMR process which efficiently pipelines these tasks is necessary for low-latency and high-throughput performance.

In the following sections, we’ll see that a core insight of efficient pipelining is to focus on achieving consensus over execution inputs rather than execution results. This requires relaxing certain constraints on what transactions may be included. We will then need to reintroduce some weaker constraints to ensure that the system remains useful and resilient to attacks (e.g., avoiding DoS vectors from transactions which don’t pay fees).
Traditional SMR
Traditional SMR (e.g., Ethereum) tightly couples sequencing and execution. Full nodes continuously sequence and execute all base layer transactions – both are prerequisites for nodes to reach consensus. In addition to verifying that all block data is available (and sequenced), nodes must also execute the block to verify that:
- All transactions are syntactically and semantically valid
- The new state computed matches the one provided by the leader
Validators will only vote for a block and build on it once they have independently verified its state. This means execution happens at least twice before consensus can be reached (i.e., block producer executes during building + receiving validators execute again to verify).
In this traditional model, building and verification both include execution.
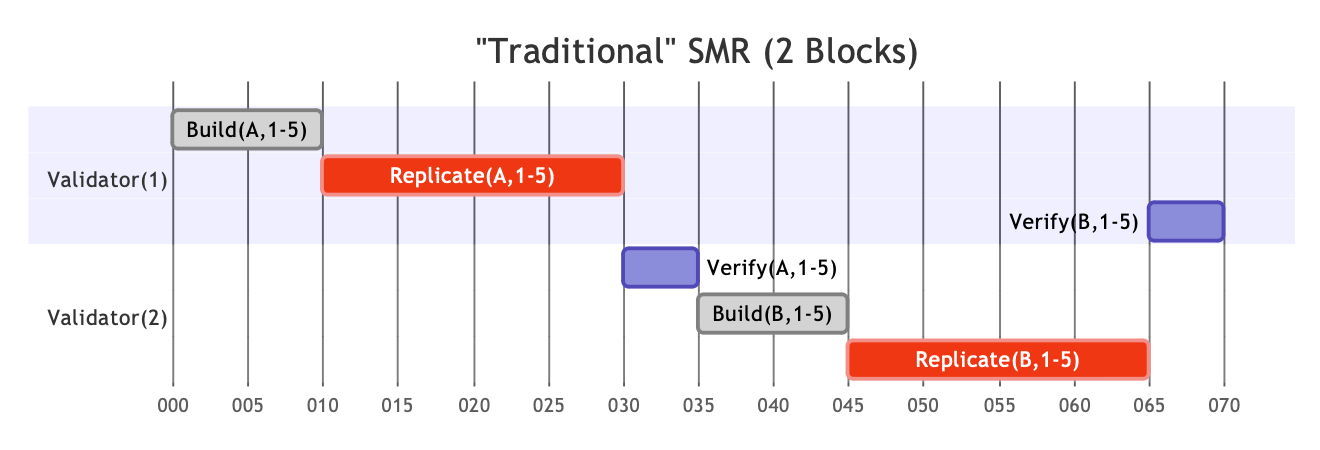
Source: Vryx: Fortifying Decoupled State Machine Replication
Streaming SMR
Streaming SMR (e.g., Solana) is an efficient form of pipelining whereby block producers continuously “stream” pieces of blocks (called shreds or chunks) as they are built. Other nodes receive and verify (including execution) these shreds continuously, even while the rest of the block is still being built. This allows the next leader to start building their block sooner.
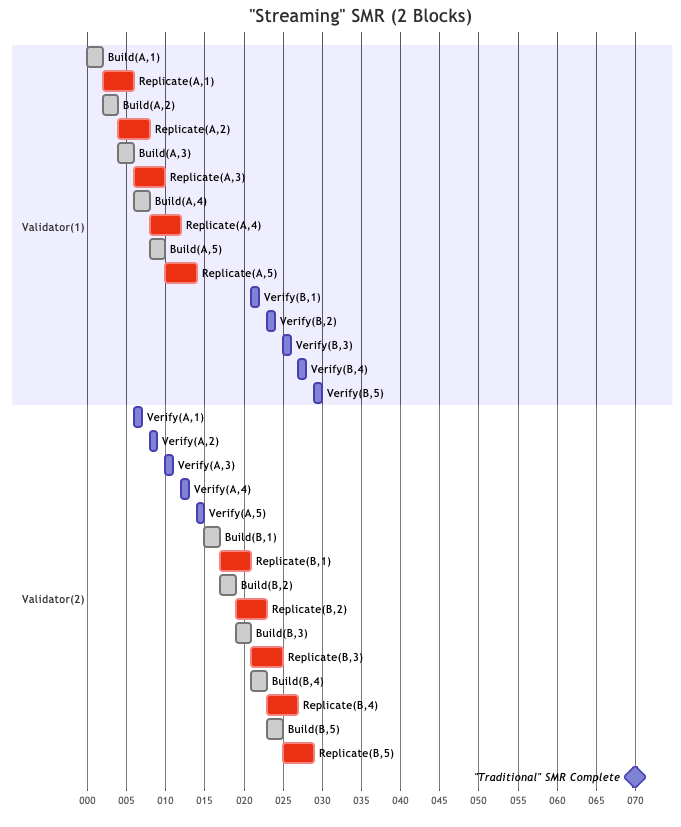
Source: Vryx: Fortifying Decoupled State Machine Replication
In this streaming model, building and verification still both include sequencing and execution. This increases SMR efficiency relative to traditional SMR without relaxing any constraints that all included transactions are both semantically and syntactically valid.
Asynchronous Execution
Integrated Approach
Now, can we get even better performance if we do relax those constraints?
Asynchronous execution removes execution from the hot path of consensus – nodes just come to consensus on the ordering of data without first executing that data. This is more efficient, which is why Solana and Monad both plan to implement asynchronous execution.
The leader would build and replicate a block (or shreds) without needing to execute it. Then, other validators would vote on it without executing it either. Nodes only come to consensus on the ordering and availability of transactions. This is sufficient because given a deterministic STF, everyone will eventually compute the same state. Execution doesn’t need to hold up consensus – it can run asynchronously. This can open up the execution budget for nodes (giving them more time to spend on execution) while reducing the steps required (and therefore time) to reach consensus.
Ordering determines the truth. Execution simply reveals it. Anyone can execute the data to reveal the truth once its ordering is finalized.
That’s probably why Keone believes that ultimately every blockchain will utilize asynchronous execution, and it’s a key piece of Toly’s endgame vision for Solana:
“Synchronous execution requires all the nodes that vote and create blocks to be over provisioned for the worst case execution time in any block… Consensus nodes can perform less work before voting. Work can be aggregated and batched, making it efficiently executed without any cache misses. It can even be executed on a different machine altogether from the consensus nodes or leaders. Users who desire synchronous execution can allocate enough hardware resources to execute every state transition in real time without waiting for the rest of the network.
Currently, validators replay all transactions as fast as possible on every block and only vote once the full state is computed for the block. The goal of this proposal is to separate the decision to vote on a fork from computing the full state transition for the block.”
It’s worth noting that we also want to make sure that the truth is revealed easily to users, and that means robust support for light clients. Some of these designs that delay execution significantly would make this challenging (e.g., Solana considering only requiring it once per epoch) vs. others that provide a state root on a shorter delay (e.g., as in the HyperSDK).
Modular Approach
That decoupling of sequencing and execution might sound very familiar because this is the “modular” approach too! Mix and match different layers which specialize in different tasks. Decoupling sequencing and execution is the key design principle of lazy sequencers (e.g., Astria):
- Sequencing – Sequencer nodes only come to consensus on the ordering and availability of rollup data (i.e., they sequence but do not execute).
- Execution – Rollup nodes execute their respective data after the sequencer has committed to it.
What if I told you that the quorum doesn’t need to execute anything either and just needs to pick forks and guess the next quorum?
— toly 🇺🇸| bip-420 (@aeyakovenko) May 2, 2024
The primary difference here is that integrated chain nodes execute after sequencing while lazy sequencers push it to an entirely different and diverse set of actors. Lazy sequencers are completely ignorant of the rollups’ state machines. They never execute these transactions. Rollups handle the asynchronous execution.
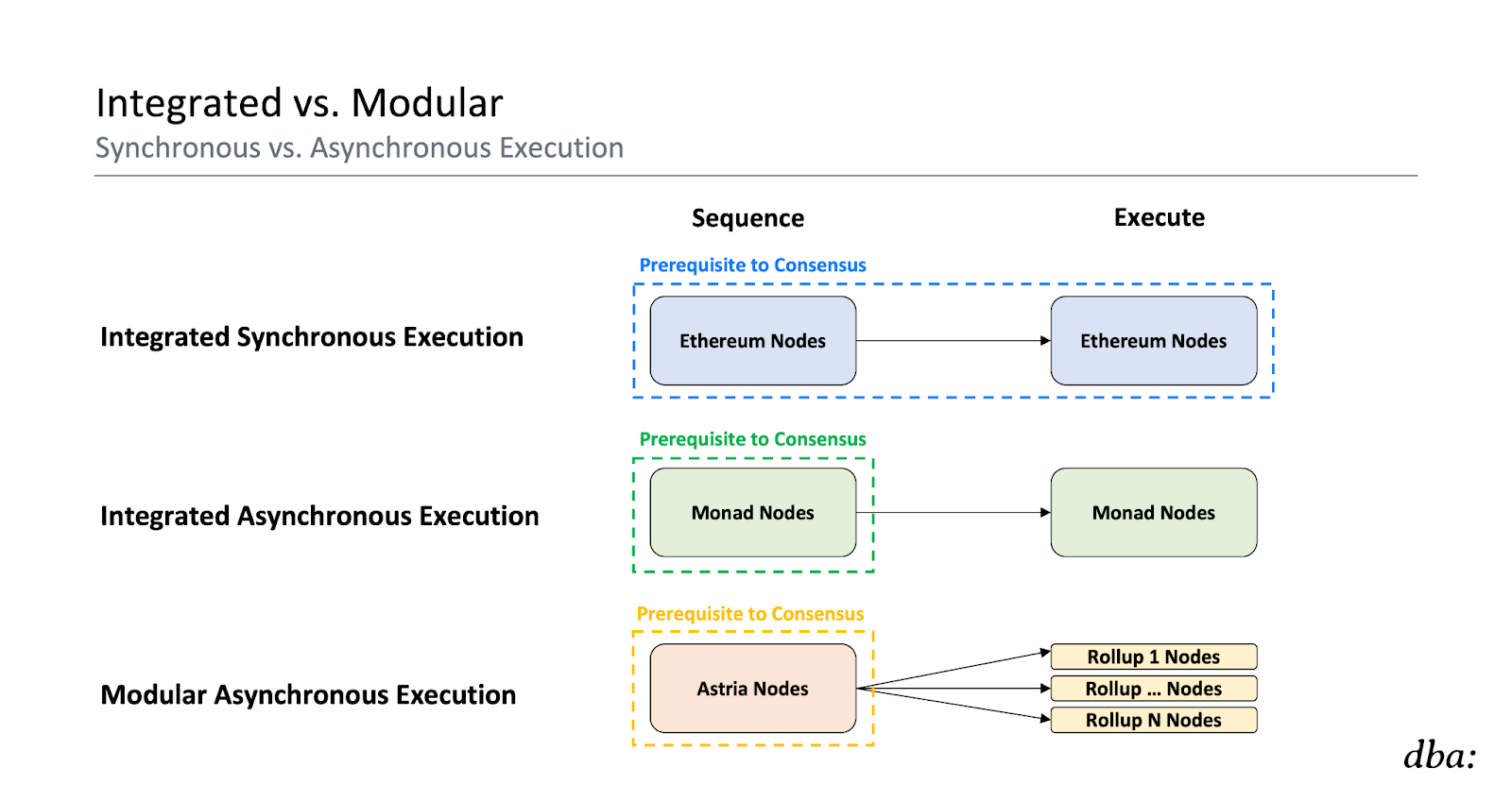
The integrated approach provides more seamless interoperability between users of the execution environment, but directionally reduces flexibility for app developers (e.g., custom VMs, different slot times, consensus-enforced app-specific transaction pricing and ordering rules, etc.). The modular approach provides more flexibility and sovereignty for developers to own customized domains, but it’s harder to unify the experience across them.
In either case, a really big and fast pipe to order data is the primitive we need:
*toly has entered the chat*
— Jon Charbonneau (@jon_charb) June 13, 2024
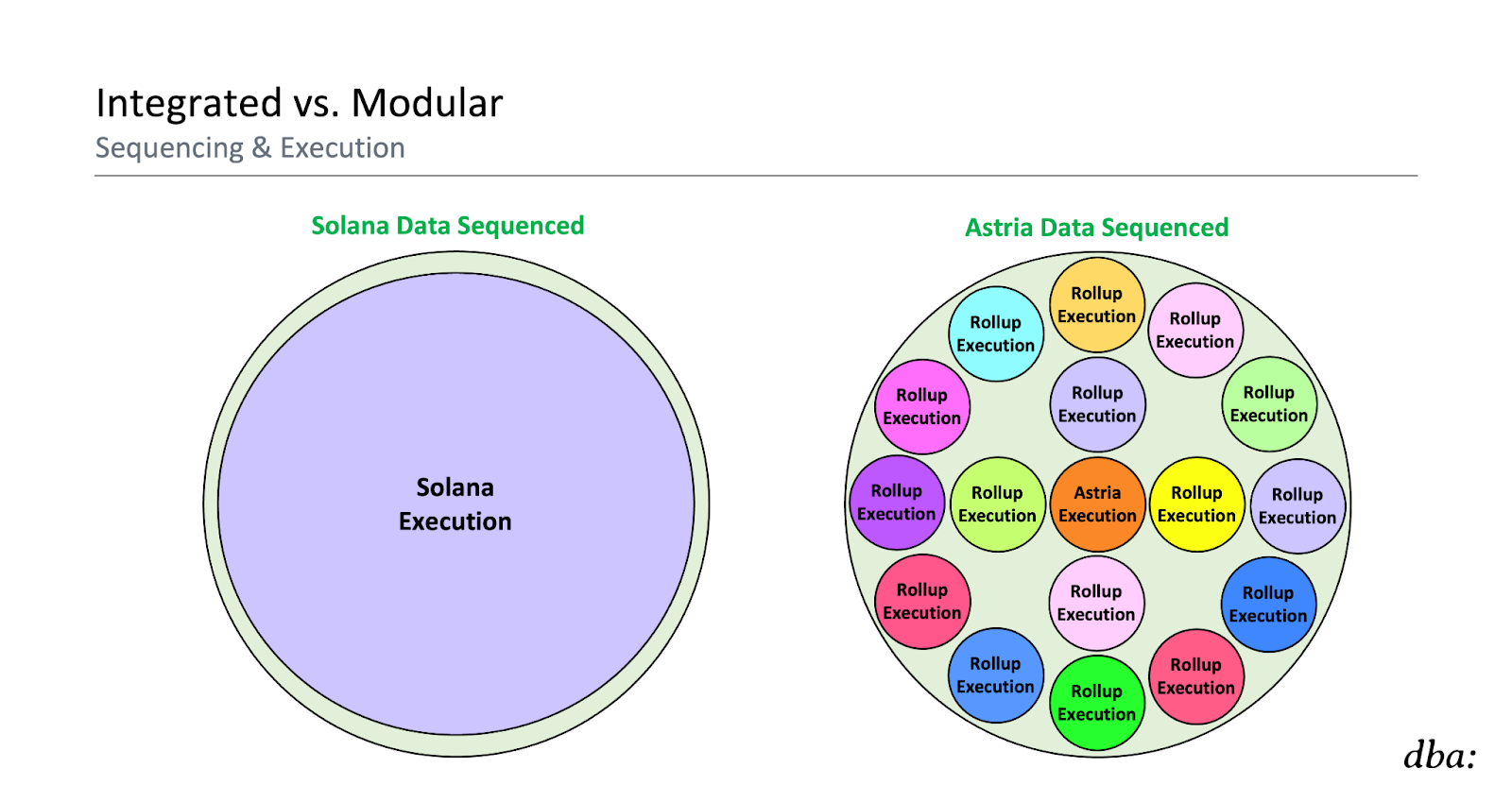
However, you should note that you can technically use pretty much any chain as a lazy sequencer. It’s just a big data pipe at the end of the day after all. A rollup can naively throw its arbitrary data onto its base layer of choice (whether that’s Ethereum, Bitcoin, Monad, etc.) to implicitly use it as their sequencer. Rollup nodes can then asynchronously execute the data after the fact.
The difference in practice is that the chains we actually refer to as “lazy sequencers” are specialized for this task, which is much easier said than done (e.g., supporting necessary transaction types, exposing easy interfaces, implementing MEV infrastructure, fast slot times, reliable transaction inclusion, high bandwidth, etc.). As a result, nodes for integrated chains end up eventually executing most of the data they include, while lazy sequencers leave that to rollups primarily.
That’s why it’s not so simple as “why don’t we just go use Solana (or any other chain when that’s never been the design goal) as a rollup sequencer?” :
- Lacking the necessary MEV infrastructure designed specifically for rollups (e.g., requisite PBS infrastructure, cross-chain interoperability mechanisms, composer to abstract fee payments for rollup users in base layer gas token, etc.)
- Lacking native transaction types designed for rollups posting data.
- Competing against the native execution environment (e.g., it’s designed explicitly to consume all or as much of the data provided as possible, leaving less room and reliable transaction inclusion, etc.).
- Competing for general developer support and upgrade prioritization. You’re probably more inclined to go to the protocol and team specialized in helping you launch rollups and designing their protocol specifically with you in mind vs. the one where most of the community thinks rollups are kinda dumb.
Fortifying Decoupled SMR
Now, can we address those problems we get by relaxing these constraints? In short, yes naive implementations do introduce problems like allowing invalid transactions which can’t pay fees (which would be DoS vector if implemented naively), but they’re addressable such that they’re not serious problems.
We won’t get too bogged down in the details here, but you can refer to Patrick O’Grady’s amazing work on Vryx to fortify decoupled SMR, Toly’s asynchronous execution endgame, and Monad’s implementation of carriage costs on how to address these issues. Again, the solutions to these problems unsurprisingly look nearly the same on both the modular side and the integrated side.
The TLDR is that you can reintroduce some much weaker constraints (compared to synchronous execution with full verification) which retain most of the performance benefits without leaving open a bunch of attacks.
In-Protocol vs. Out-of-Protocol Actors
Importantly, we need to realize that the above processes naively only accounted for in-protocol actors. In reality, out-of-protocol actors play a huge role in these transaction supply chains. This is what we saw earlier for (in-protocol) validators in traditional SMR:
Source: Vryx: Fortifying Decoupled State Machine Replication
In practice though, nearly all Ethereum validators outsource block building via MEV-Boost with the top three builders (Beaver, Titan, and rsync) building nearly all of these blocks. Note that Beaver and rsync censor OFAC transactions while Titan does not.
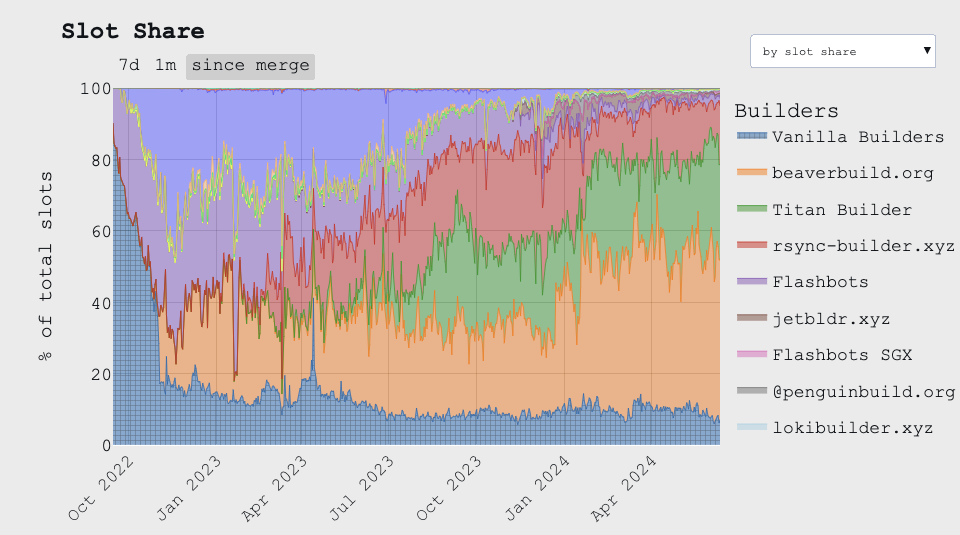
Source: mevboost.pics
Relays handle replicating these blocks to the rest of the network. They’re also relatively topheavy, with the top four operators (ultra sound, bloXroute, Agnostic, and Flashbots) relaying the vast majority of blocks. bloXroute and Flashbots censor OFAC transactions, while Agnostic and ultra sound do not.
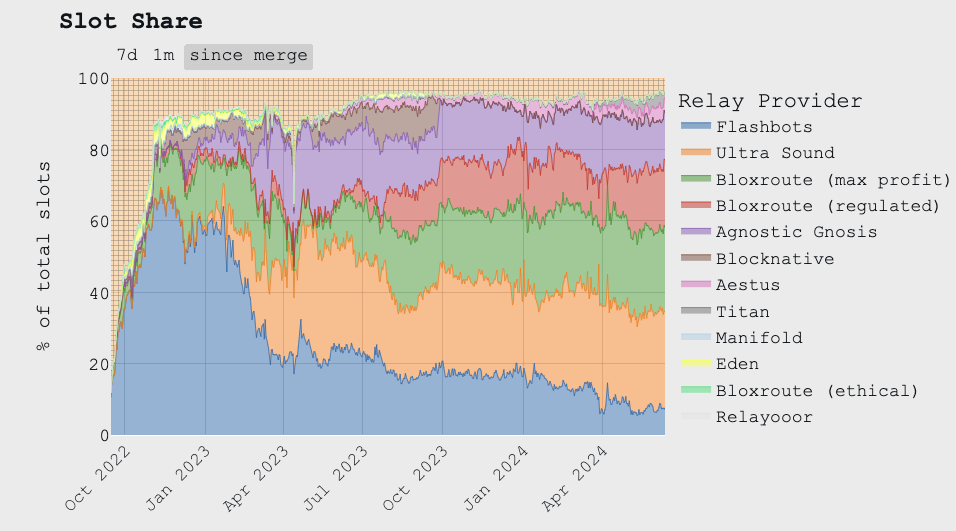
Source: mevboost.pics
It should also be no surprise that we see very similar trends in latency optimizations here as we discussed earlier. The trend is toward optimistic relays which no longer perform block verification prior to replication because it’s simply faster. Lazy sequencers can be viewed as incentivized relay networks.
These examples highlight how MEV skews the profit incentives in these systems. Validators outsource block production because sophisticated builders can capture more value vs. naively sequenced blocks.
Even under asynchronous execution, there will often be out-of-protocol block producers executing transactions during building to maximize value. For example, it’s very likely that lazy sequencers will have profit-maximizing builders in some form of PBS. The fact that an external block producer is always incentivized to still fully execute and optimize the value of a block can actually be useful in settings where we relax constraints in async execution. Still though, other validators wouldn’t need to re-execute prior to voting.
Universal Synchronous Composability
Definitions
Now, can we get the sovereignty and flexibility that modular chains offer, but reunite them to feel like an integrated chain? Can we have our cake and eat it too, or do we just end up building Solana with extra steps?

When listening to people talk about fixing rollup fragmentation, you’ve probably heard the big buzz words around universal synchronous composability (USC). However, this has probably been your reaction:

These terms all get thrown with different meanings, and some terms are often incorrectly used interchangeably. We need to set some concrete definitions. We define the necessary terms below in the context of cross-chain composability.
Note that we’ll discuss “rollups” throughout the rest of this report, but many of these concepts apply equally to other types of “L2s” such as validiums. I just don’t want to fight over wtf is an L2 again.
In the following examples:
- RA = Rollup A
- RB = Rollup B
- TA1 = Transaction 1 on RA
- TB1 = Transaction 1 on RB
- BA1 = Block 1 on RA
- BB1 = Block 1 on RB

Note that we define “time” to be “slot height” here. Time is purely relative to the observer. The only objective notion of time we have is a relative ordering by a shared observer, i.e., a shared consensus (where that “consensus” may be a single actor or a decentralized mechanism).
If both rollups each have a consensus mechanism which provides ordering, we can assert:
- BA1 is before BA2
- BB1 is before BB2
However, the only way to assert:
- BA1 is at the same time at BB1, and therefore
- TA1 and TB1 happen synchronously, is if
- they share an ordering provided by a shared consensus for that given slot.
Therefore, cross-chain synchronous composability definitionally requires some type of shared sequencer for that slot height. Chains without one can only ever have asynchronous composability.
However, note that we can have asynchronous atomic composability. Unfortunately, I often notice people use “atomic” and “synchronous” interchangeably, but they are indeed different terms.
With that out of the way, let’s see if we can reintroduce synchronous composability into modular chains. If we can, then that may seem to negate the value of integrated chains. This is the TLDR that we’ll dive into:
- Shared sequencing can provide synchronous atomic inclusion on its own (which is much weaker than composability).
- Pairing a shared sequencer with some mechanism for cryptographic safety (e.g., AggLayer) can strengthen this inclusion guarantee into actual composability.
- The safety guarantees provided by the AggLayer for cross-chain safety can also be used without a shared sequencer (i.e., in the asynchronous setting).
- We’ll see how we can also simulate the effects of synchronous composability, albeit in a less capital efficient manner, using cryptoeconomics (directly collateralizing cross-chain transactions).
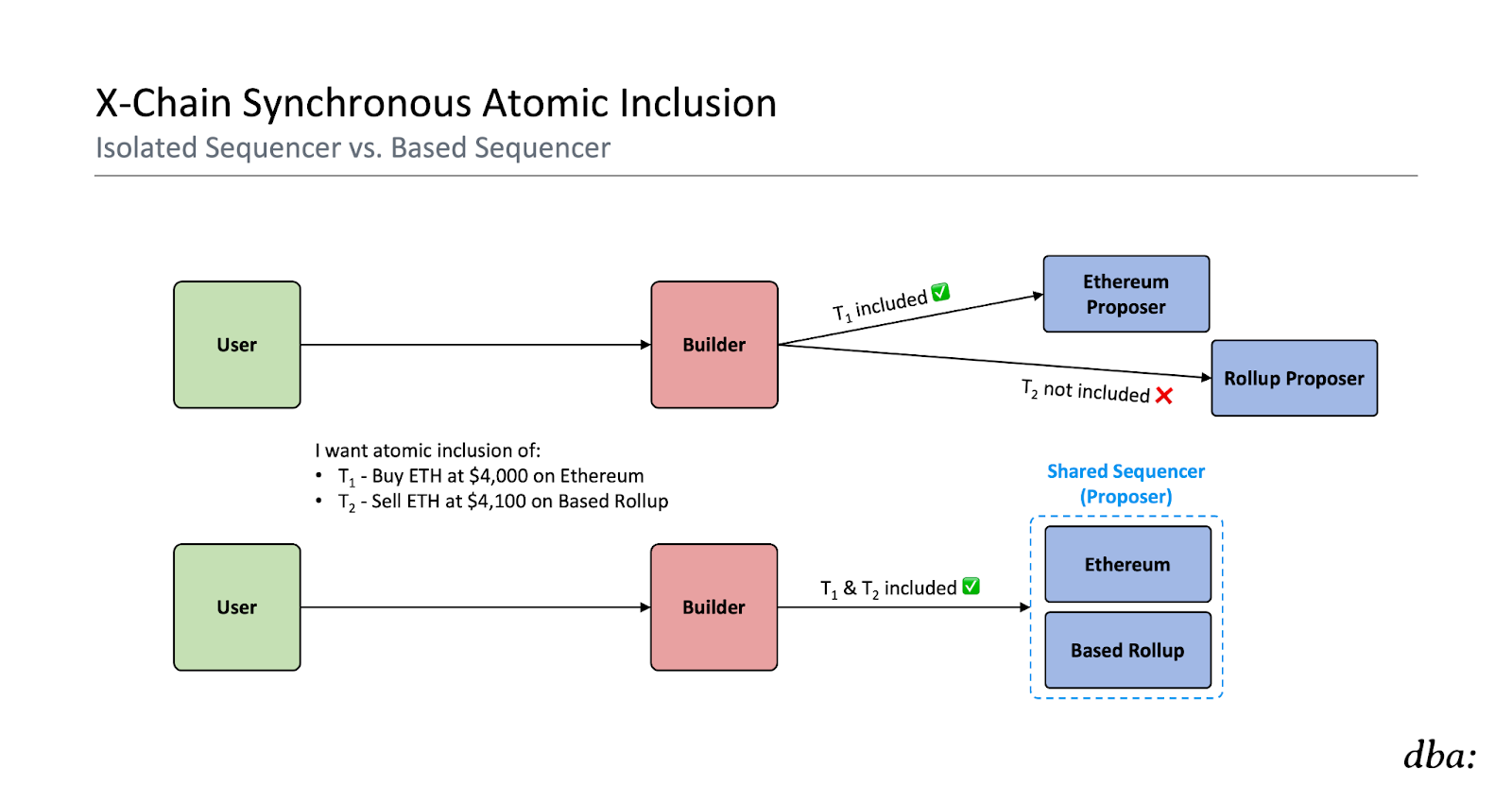
Atomic Inclusion – Shared Sequencing
Shared sequencing means that for a given slot height, a single entity (the “sequencer” a.k.a. the “proposer”) has monopoly rights to sequence (i.e., propose blocks for) multiple chains. To reiterate, these shared sequencers we generally speak about are lazy sequencers. They reach consensus on the ordering and availability of rollup data, but they do not execute it. They are completely ignorant of the rollups’ state machines.
As I’ve written previously, this means that lazy shared sequencers can provide a credible commitment to include cross-chain bundles (i.e., a set of transactions):
- Atomically – either all transactions will be included or none will, and
- Synchronously – at the same time (slot height)
This enables more efficient MEV extraction by super builders (i.e., cross-chain builders) when performing cross-chain actions, as they no longer have to price the risk that one leg of the cross-chain bundle may fail. The synchronicity here is able to implicitly provide them atomicity.
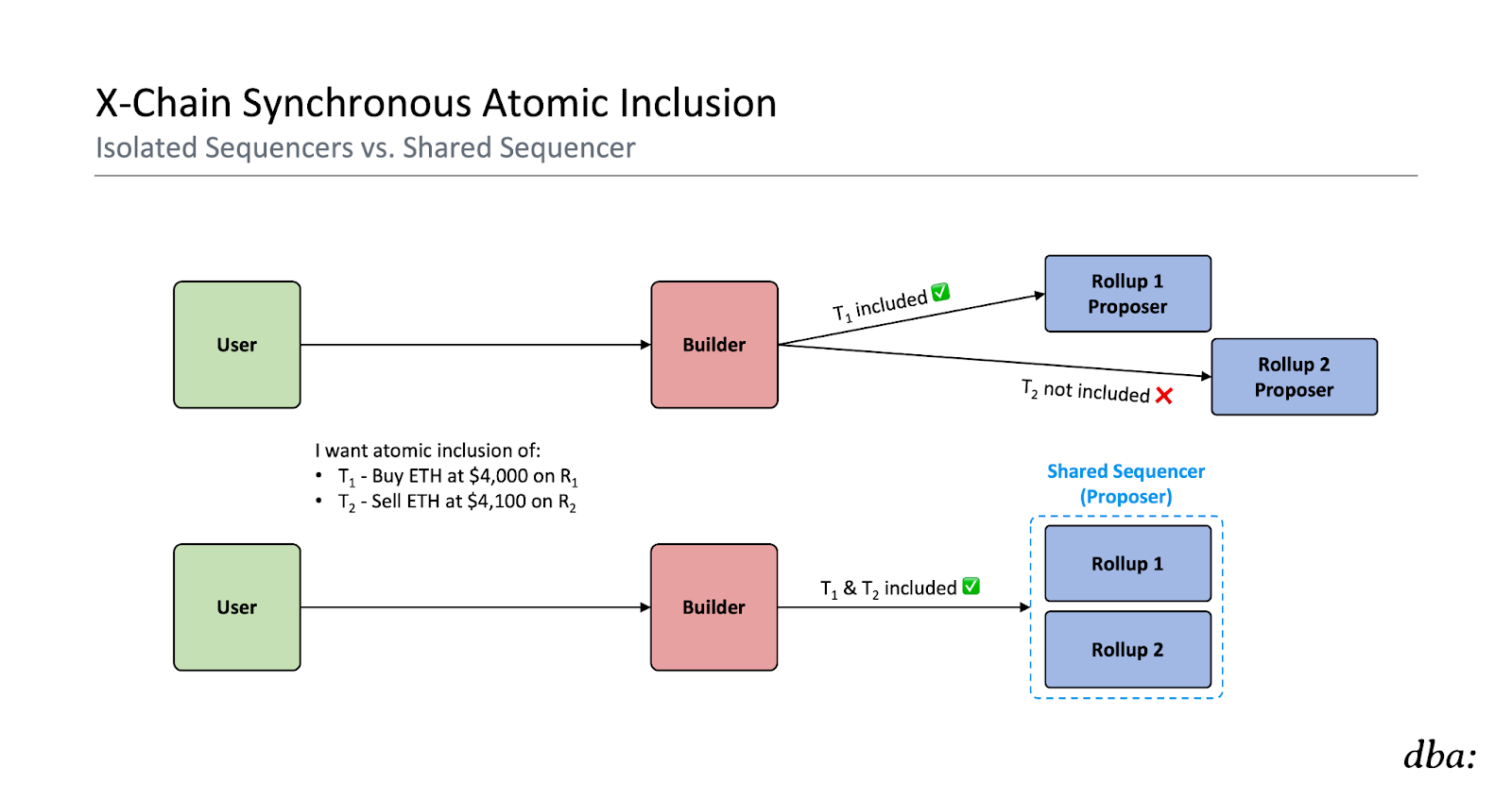
Cross-chain Unbundling
Now, how exactly do we do this without fully trusting the builder and/or active proposer for the shared sequencer? If we just send two independently signed transactions (T1 and T2) for each rollup, the shared sequencer could still decide to just include one or the other.
For example, there’s no notion of a native bundle format in the EVM today, which is why searchers entirely trust builders/relays not to unbundle them. Anyone that sees a bundle of independently signed transactions prior to them being committed to by the current leader can unbundle them. This is generally fine, because builders and relays are incentivized to maintain their reputations and protect searcher bundles, but when that trust is broken (or they’re tricked by dishonest participants to reveal the transactions), unbundling can be incredibly profitable.
We need a much stronger safety guarantee here if we want real cross-chain interoperability. We’re not just talking about taking some money from a searcher. If cross-chain DeFi contracts were to architect themselves on the assumption that the cross-chain bundles will be respected, but then this trust is broken, the results would be catastrophic for those protocols (e.g., in a burn-and-mint cross-chain bridge bundle, you could leave out the burn but mint funds on the other side).
We need ironclad safety guarantees to implement cross-chain interoperability. That means we must define a transaction format which ensures that multiple transactions in a cross-chain bundle are included together. If one is included without the other, we need a safety guarantee that the one that is included is invalid.
This means we need to create a new transaction structure for cross-chain bundles which cannot be unbundled. The naive solution is “let’s just make a new transaction type for these rollups,” but that’s not so easy. It would require VM changes for these rollups, losing backwards compatibility. You’d also be tightly coupling the rollups by modifying their state machines such that each transaction is only valid together with the other being included.
However, there’s a cleaner way to do this. You can have each transaction in the bundle also sign the bundle hash, then append the hash digest to a free transaction field (e.g., calldata in the EVM). The rollup must modify their derivation pipeline to check these, but the VM can remain unchanged. With this in place, rollup users could submit cross-chain bundles that they’re certain cannot be unbundled. Attempting to do so would invalidate them.
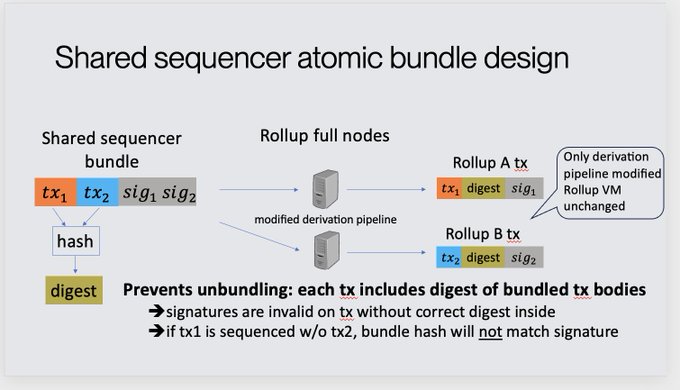
Source: Ben Fisch
Inclusion Guarantees vs. State Guarantees
With the above in place, we’ve now established how a lazy shared sequencer:
- Can provide a credible commitment of atomic synchronous inclusion for cross-chain bundles (i.e., that all transactions will be included, or none will)
- Cannot provide a credible commitment around the resulting state from such transactions being included (e.g., it’s possible that both transactions are included, but some other transaction lands ahead of it and causes it to revert)
Unfortunately, atomic inclusion on its own is a much weaker guarantee. This commitment to atomic inclusion is enough for the builder to have high confidence that the cross-rollup block they build will create the resulting state they want if it is confirmed. The builder necessarily knows the resulting state of the block, because they executed it to build it.
We still have a problem though – how does everyone else know with certainty what the state will be?
Consider an example:
- We have two rollups (RA and RB) sharing the same lazy sequencer
- I want to use a burn-and-mint bridge between RA → RB which simultaneously burns on RA and mints on RB
- The minting bridge contract on RB needs a guarantee of the state transition on RA (burn) to mint on RB, but the contract can’t know if the token was actually burned on RA at the time of execution because it doesn’t have access to the state of RA
If we submitted a proper bundle, then the lazy sequencer can guarantee that the burn transaction was included in the transaction stream for RA, but you don’t know for example if maybe another transaction landed in front of it that invalidated it (meaning the tokens weren’t actually burned).
Simply sharing a lazy sequencer is insufficient to enable chains to access each other’s states during bundle execution. Synchronous composability requires the ability for state machine of each chain to access the other chain’s state (e.g., the bridge contract itself on RB needs to know the state of RA) at the time of execution. That capability is exactly what enables full composability within a single integrated chain.
The builder can’t just tell the contracts “trust me bro, it’ll work out.” We see that atomic inclusion is a nice tool for searchers who trust builders to properly execute their bundles, but it is insufficient for abstracting away cross-chain interoperability.
can you ensure rollups A + B both receive a tx bundle?
can you ensure both rollups A + B both execute the contents of the tx bundle?
during bundle execution, can A or B access the other’s state?
— James Prestwich (@_prestwich) August 5, 2023
To fix this, we need to add some other mechanism in addition to shared sequencing:
Yes, indeed, shared sequencing gives the property of *atomic inclusion*.
To translate that into the property of atomic composition, requires a cryptoeconomic or ZK layer on top.
— Sreeram Kannan (@sreeramkannan) April 1, 2024
As we mentioned, the builder personally knows what the resulting state will be though if the bundle is included atomically. So how can they provide a credible commitment to convince everyone else about what the resulting state will be if their transactions are included?
They broadly have two options:
- Cryptoeconomic – The builder can stake a large amount of capital to fully collateralize their cross-chain actions. This is often inefficient and arguably simulated composability, but it’s a helpful example to demonstrate the functionality.
- Cryptographic – We can have a mechanism which provides cryptographic assurances that the transactions will produce the desired state.
Cryptoeconomic Safety – Builder Bonds
Let’s walk through an example to see how cryptoeconomics could simulate the effects of synchronous composability. The classic example used is that of a cross-chain flashloan. I want to take out a flash loan on RA, use it for an arbitrage on RB, and return it on RA all in the same slot. This is possible if these DeFi protocols here deploy customized cross-chain functionality with what we’ll call “bank contracts” on each side:
1/ Shared sequencers may be way more powerful than we thought.
The Espresso team recently laid out how shared sequencers could enable atomic composability, even flash loans.
Here’s how a flash loan could work 🧵 pic.twitter.com/s9xH5eLI02
— Sanjay Shah ⚡️ (@sanjaypshah) August 2, 2023
Now for that safety problem – the contract on RA and RB need to know each other’s chain states to do this safely, but we have done nothing to address this. Well the cryptoeconomic “solution” here is actually rather brute force – you have the super builder act as a liquidity provider and put up the full value of the flash loan. If the transactions were to fail, then the lending protocol just keeps their stake anyway. You can see why this isn’t the most satisfying “solution”.
cool design where you *checks notes* double the capital requirements of *squints* everything https://t.co/DOOSpZZP6g
— James Prestwich (@_prestwich) August 2, 2023
It’s well understood that atomic inclusion can only achieve atomic execution with another mechanism
This bank mechanism is extremely expensive, and only works for a small class of transactions. Wow.
there are multiple cheaper, general purpose, mechanisms out there already.
— James Prestwich (@_prestwich) August 2, 2023
Cryptographic Safety – AggLayer
What it is
The AggLayer is a decentralized protocol that provides three major benefits:
- Safety for Fast Cross-chain Composability – It produces ZK proofs that give AggChains cryptographic safety for atomic cross-chain interoperability at low-latency (i.e., faster than Ethereum blocks) when operating asynchronously or synchronously. The design uniquely isolates chain faults so that it can support any execution environment and prover.
- Cross-chain Asset Fungibility – It has a shared bridge to ensure asset fungibility across AggChains (i.e., the chains that use it) so that users don’t end up with a bunch of wrapped assets. The bridge contract is on Ethereum which is the settlement layer. (Note that different chains can still have different security assumptions due to implementation, which is covered more below.)
- Gas Optimization – It aggregates proofs for AggChains to amortize fixed costs across many chains. The shared deposit contract also optimizes gas costs by allowing for direct L2-to-L2 transfers without touching the L1.

Source: Brendan Farmer, Aggregated Blockchains
To clarify two common misconceptions about what the AggLayer is not:
- The AggLayer is not just a service to aggregate proofs – This is confusing because it does in fact aggregate proofs, and they put “aggregation” in the name of the thing. However, AggLayer’s purpose is aggregating chains. The important distinction for the purposes of this post is that proof aggregation alone does nothing to achieve the safety guarantees we need here.
- The AggLayer and shared sequencers are not opposing designs – While they do not need to be used together, they are in fact perfect complements which provide different guarantees. The AggLayer is completely agnostic to how AggChains are sequenced. It does not handle any of the messaging between the chains, so it actually explicitly relies on free-market coordination infrastructure (e.g., relays, builders, isolated sequencers, shared sequencers, etc.) to compose the chains.
Now let’s walk through how it works.
Bridging Sucks
Bridging between rollups today sucks. Let’s say you want to bridge ETH between two Ethereum optimistic rollups ORUA and ORUB:
- Via native bridge – You’ll pay expensive Ethereum L1 gas fees (i.e., bridging from ORUA → Ethereum + Ethereum → ORUB), and the roundtrip will take over a week (because of the fault proof window).
- Direct rollup → rollup – The wrapped ETH you receive on ORUB wouldn’t actually be fungible with the native ETH for ORUA. The path dependency of going through different bridges breaks fungibility. For example, if the ORUA bridge was drained, then the wrapped ETH you bridged to ORUB would be unbacked, while the native ETH on ORUB would be fine. Liquidity fragmentation sucks, so this isn’t something that users want. In practice, users directly bridge via liquidity providers. Someone will front you the ETH on ORUB and keep your funds on ORUA. They can withdraw via the native bridge and wait, but they will charge expensive fees for the risk and high cost of capital they incur.
You may think that ZK rollups solve this right off the bat, but they actually don’t. Naive implementations still require you to submit L1 transactions, which is again expensive and typically quite slow (e.g., due to Ethereum finality times, proof generation times, how often proofs are posted in practice, etc.).
Users don’t want to deal with this. They want to just have funds and use apps. Bridging should be completely abstracted – assets should be fungible and move quickly, cheaply, and safely.
This is where sharing a bridge contract comes in. A shared bridge contract opens the door for chains using it to bridge directly between each other without going through the L1.
Tokens can also be fungible across AggChains as a result. Bridging ETH from RA → RB or RC → RB burns and mints the same token. It’s not a lock-and-mint wrapped asset. It’s native ETH. This is possible because all assets are escrowed together and settled via the unified bridge. This is a major pain point for L2s today that needs to be addressed.
You definitely will still know there are multiple chains
Wallets go out of their way to show you multiple chains! These assets are not fungible! pic.twitter.com/rYG9Wl4DTJ
— Integrated Kyle e/acc (@KyleSamani) June 4, 2024
However, note that a user holding ETH on RA vs. RB could have a different risk profile if the different chains use different verifiers (e.g., perhaps you moved from a safe chain to one with a circuit bug). Risk profiles are unchanged among chains using common standards here (which in practice is the norm today). More uniform standards and formal verification will only improve this over time even as heterogenous domains are added.
Pessimistic Proofs
AggChains submit their state updates and proofs to AggLayer staked nodes who arrange them, generate commitments to all messages, and create recursive proofs. The AggLayer then generates a single aggregated ZK proof (which they call a “pessimistic proof”) to settle to Ethereum for all AggChains. Because proof aggregation here amortizes costs across arbitrarily many chains, it’s practical from a cost perspective to post them to Ethereum for fast settlement ASAP. The pessimistic proof program is written in regular Rust code, using Succinct’s zkVM SP1 for ease of development and high performance.
These pessimistic proofs enforce:
- Interchain accounting – Proves that all bridge invariants are respected (i.e., no chain can withdraw more tokens than have been deposited to it).
- AggChains’ validity – Proves that each chain has updated their state truthfully, with no chain equivocations or invalid blocks.
- Cross-chain safety – Proves that state updates that are the result of cross-chain transactions at lower than Ethereum latency are consistent, and can be settled to Ethereum L1 safely. This includes successful atomic execution of cross-chain bundles both synchronously and asynchronously.
With this, the AggLayer ensures that settlement occurs on Ethereum if and only if the above conditions are met. If they are not met, then the respective chains cannot settle. As such, the AggLayer can allow a coordinator (e.g., a shared sequencer or builder) to pass messages between chains at low-latency without them trusting that coordinator for safety.
Fast & Safe Cross-chain Interoperability
AggChains can use the guarantees provided here in both the asynchronous and synchronous interoperability settings to express constraints on block validity relative to other rollups.
This would enable users to submit cross-chain bundles which must be successfully executed atomically on both sides. Not just atomic inclusion. You’re actually enforcing the resulting state of them must be successful. This is the perfect fit to augment exactly what we described as lacking in the atomic inclusion guarantees of a shared sequencer alone.

Source: Brendan Farmer, Aggregated Blockchains
Taking our example from earlier:
- We have two rollups (RA and RB) sharing the same lazy sequencer and the AggLayer
- I submit a cross-chain bundle to simultaneously burn ETH on RA and mint ETH on RB
- A super builder builds a block for both chains doing this, which the shared sequencer commits to
- The minting bridge contract on RB can optimistically mint the ETH contingent upon the state of RA (in this case, successfully executing the ETH burn)
- These blocks and proofs are submitted to the AggLayer, which proves that both chains acted in a valid way (both independently and with respect to each other) and that the shared bridge was used safely
For this to be settled to Ethereum successfully, both legs of the bundle must have executed properly. If either side fails, then the blocks would be invalid and cannot be settled. That means that if say the shared sequencer signed off on a block where the ETH was not burned on RA but minted ETH on RB, then that block would be reorged. This ensures the safety of all chains and prevents dishonest cross-chain actions from being settled.
There are two points to keep in mind with respect to these reorgs:
- They would be incredibly short because they would be detected and proven immediately.
- They can only happen if the coordinator (e.g., sequencer and/or builder) of the chain you are connected to is actively malicious.
These reorgs should be exceedingly rare and minimal due to the above points, but because of this AggChains will have full control over which chains they want to compose with atomically and under what trust assumptions. For example, RA may accept a chain state from RB to compose with based on their sequencer’s consensus, but for RC it may want a proof submitted as well, and for RD maybe they want them to crypto-economically secure all cross-chain atomic dependencies. Every chain can make their own customizable tradeoffs here for low-latency and liveness. AggLayer just provides the maximally flexible and minimally opinionated foundation for chains to have safe cross-chain interactions.
You can also see here why such a design is in practice incompatible with a fault proof based design. In theory they could do this, but in that case it would be possible to experience incredibly deep reorgs. Quickly proving and settling all chains bounds the worst case to be very short, which also acts as a natural deterrent for any malicious attempts.
Fault Isolation for Heterogeneous Provers
Importantly, the AggLayer uniquely enables completely heterogeneous chains. You can have an AggChain with whatever custom VM, prover, DA layers, etc. while safely sharing a bridge with everyone.
How is this possible though? The reason why this normally isn’t acceptable is because a single faulty participant (e.g., with a circuit bug) could normally just trick a bridge and drain it of all funds. Well that’s where the interchain accounting proof mentioned above comes in. These proofs ensure that the bridge invariants are all respected, so that even in the case of an unsound prover, only the funds deposited to the affected chain could be drained. The fault is completely isolated.
Credible Neutrality
This type of infrastructure is greatly benefitted by credible neutrality, which is why the fully open-source code ifor AggLayer is neutral territory. In a similar spirit, the AggLayer will use ETH as the sole gas token to pay fees for proof aggregation.
It’s certainly not perfect though. Especially at the start, it won’t be entirely credibly neutral. There’s likely to be contract upgradability on the path to eventual immutability and enshrinement as a public good.
That being said, it doesn’t have to be perfectly credibly neutral, nothing is. (We’ll see this again below with based rollups.) In practice, it offers probably the most compelling technical competing vision, and it takes an intentionally minimalist attitude towards lock-in and rent extraction. The goal is to allow AggChains to maintain as much sovereignty as possible, while still being able to abstract away trust-minimized cross-chain composability.
AggChains don’t need any specific VM, execution environment, sequencer, DA layer, staking token, gas token, or common governance. Chains can leave when they want. There’s no revenue share requirements. You don’t need to deploy as an L3 on someone else’s chain.
L2s aggressively pushing L3s is a strategic business move rather than a scaling one, and one that Ethereum L1 should be cautious of the power dynamics
— Jon Charbonneau (@jon_charb) March 9, 2024

The reasons to launch L3s on top of general L2s have mostly in my view been band-aids while architectures similar to the AggLayer are being built. To be clear though, that’s a totally valid reason to launch them today. The v1 AggLayer is just a simple shared bridge contract. The v2 with proof aggregation and the ability to get safe low-latency interop isn’t even live. You can’t expect people to wait around for years when they have an urgency to ship a thing today that’ll get them the fastest distribution.
Real-time Proving
While several years away from being practical in any low-latency settings, we should note that real-time proving could also potentially be used alongside shared sequencing for cross-chain safety. It’s also just cool, so we’ll cover it briefly. More specifically, “real-time” proving refers to proving times that are shorter than the slot times of the chain in question. Let’s consider the cross-chain mint-and-burn bridge example again:
- We have two rollups (RA and RB) sharing the same lazy sequencer
- I want to use a burn-and-mint bridge between RA → RB which simultaneously burns on RA and mints on RB
- The super builder creates a cross-chain block which includes a bundle of these cross-chain transactions. Inside of the blocks, the builder includes a proof of the state transition that’s being included on the other rollup.
We already had the shared sequencer’s guarantee of synchronous atomic bundle inclusion, and now each contract can verify a proof of the other chain’s state to know it will execute successfully.
For real-time proving, we ideally want the proving time to only be a small fraction of the total slot time, thus maximizing the “synchrony window.” This is the portion of the slot time in which you’re able to process transactions which would operate synchronously cross-chain, as you need to budget enough time in the slot to create the proof and land it in the block.
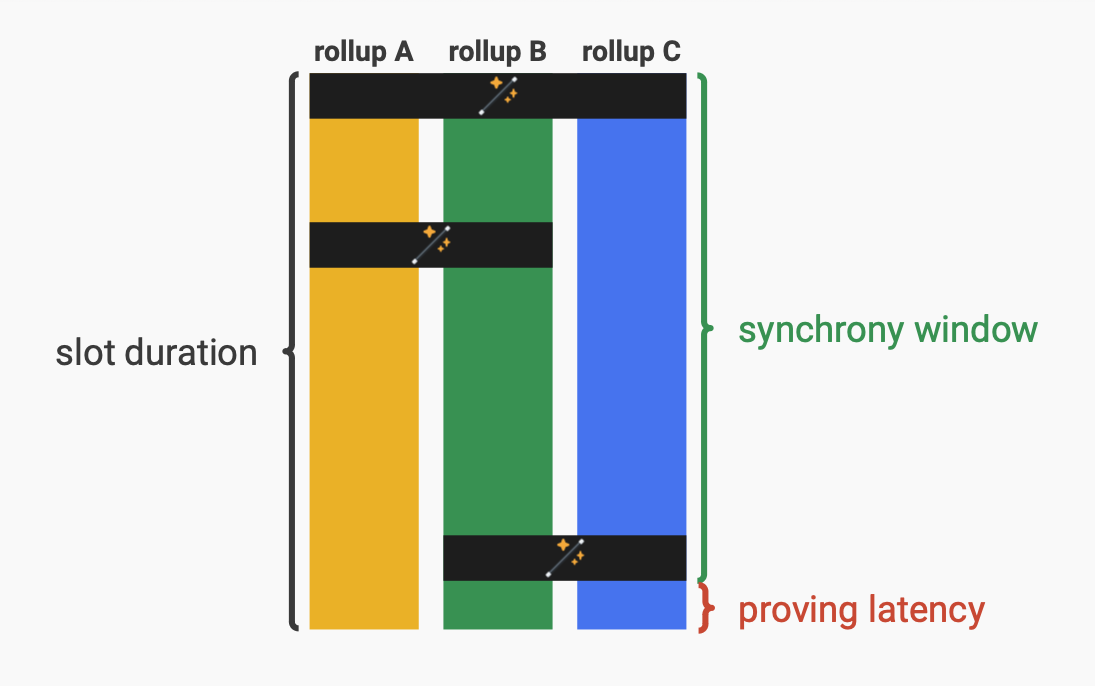
Source: Justin Drake, Real-time Proving
Note that we would implicitly end up merging or collocating builders and provers here. There’s a clear incentive for builders to optimize proving speeds so that they can build up to the last second and fit as much as possible in their block.
Source: Justin Drake, Real-time Proving
If this high incentive for real-time proving does materialize in the coming years, we should also note that this is of course not at all friendly to decentralized proving. Provers would need to be relatively centralized as they merge or collocate with builders.
Summary
Universal synchronous composability is really cool, but it’s not super clear how valuable it actually is. The internet is all asynchronous and you’d never know it. That’s because it’s fast and complexity is abstracted. That’s all users want.
I expect that most of the value of using something like AggLayer won’t just be in the synchronous setting. Rather, it’s the fact that it can act as a form of cross-rollup chain abstraction. Make many chains feel more like one with the user-facing aspects that matter (e.g., more fungible native assets, natively cross-chain app functionality, fast interoperability, etc.).
Synchronous atomic composability is very overrated imo. Like, think about what are some specific cross-L2 things *you* are already doing or envision yourself doing that could be more seamless. For me, the top two are:
1. I have coins on Optimism, I want to pay Bob, but Bob is…
— vitalik.eth (@VitalikButerin) June 19, 2024
yea I definitely agree, I mostly see synchronous interop as MEV extraction tool
users want “low-latency” not “synchronous”, good async interop with cross-chain UX abstracted is what’s needed 99% of time
that’s why I think something like agglayer would end up being used imo…
— Jon Charbonneau (@jon_charb) June 19, 2024
Synchronous composability is clearly financially valuable (e.g., allowing liquidations, more efficient arbitrage, more efficient refinancing using flash loans). However, similar to how the internet is asynchronous and works just fine, TradFi is of course asynchronous. It’s reasonable to want to be even better than TradFi, but we should be clear that universal synchronicity is not a requirement for good execution. There’s also a real cost to building and providing synchronous infrastructure.
I personally think the best argument in favor of needing USC is that in practice it does lead to better UX and DevEx. It’s impossible to deny the gigantic benefit this has been to ecosystems such as Solana. However, this is hopefully more of a today issue and not a forever issue.
the best argument for synchronous interop imo is just that in practice its the easiest way to get good UX
eg just simplifying devex a lot / not having to deal with as many edge cases / easier to build protocols around it and UIs etc
— Jon Charbonneau (@jon_charb) June 19, 2024
The simple fact of the matter is it’s also just somewhat difficult for anyone to reason about at this stage. This isn’t a binary “everything in crypto is synchronous” or “everything is asynchronous.” I think we will fundamentally need to solve for and gravitate towards the latter, but both can exist on an ad hoc basis.
Great framing of three features by @0xfoobar.
If you want sync composability *all the time* across a set of apps, you need to also pay for the cost of joint consensus.
But if you want sync composability only some times *on demand*, you can pay for the cost of consensus only… https://t.co/kLTE56wpBk
— Sreeram Kannan (@sreeramkannan) February 16, 2024
Ethereum Based Rollups
Ok, so now we should have a good idea of the solution space for addressing fragmentation in rollups. The next question is how should we involve the base layer in all of this? What is Ethereum’s role here?
We will use the following abbreviations throughout:
- BL – base layer
- BR – based rollup
- Preconfs – preconfirmations
Unless otherwise noted, the BL in question that we’ll be discussing is Ethereum, and the BRs are Ethereum BRs. However, the basic concepts apply broadly as you could launch BRs anywhere.
Vanilla Based Rollups
The initial rollup implementations several years ago were actually planned to be BRs, but were abandoned in favor of centralized sequencers for low-latency and high-efficiency. What we now call based sequencing, Vitalik referred to as “total anarchy” at the time. It was relatively impractical and inefficient prior to the evolution of Ethereum’s PBS infrastructure (with sophisticated builders).
BRs were then brought back into the limelight in March 2023, where they were defined as follows:
“A rollup is said to be based, or L1-sequenced, when its sequencing is driven by the base L1. More concretely, a based rollup is one where the next L1 proposer may, in collaboration with L1 searchers and builders, permissionlessly include the next rollup block as part of the next L1 block.”
They should offer the following benefits:
“The sequencing of such rollups—based sequencing—is maximally simple and inherits L1 liveness and decentralisation. Moreover, based rollups are particularly economically aligned with their base L1.”
Specifically, you get the real-time security of Ethereum:
“You inherit the censorship resistance and the liveness of Ethereum. So not only do you have the settlement guarantees of Ethereum, but you also have the censorship resistance, the real-time censorship resistance, not the delayed one you know with the escape hatch, but the real-time one.”
Being a based rollup is the logical design once you’ve picked a base layer:
“Ethereum is maximizing for these two properties, security and credible neutrality, it’s almost the definition of a rollup right… A rollup is one that has already bought into the security assumption of Ethereum. You’re not adding a new security assumption. You’re not falling to a weakest link. You’re just reusing the existing security assumption. And two is you’ve already accepted Ethereum as a credibly neutral platform otherwise you would have chosen another chain. And now you can go ask yourself why isn’t everyone just using the layer one sequencing?”
In their simplest form, BRs can certainly achieve the above design goals. If the rollup doesn’t implement its own sequencer, then implicitly the current Ethereum proposer decides what will be included every 12s (Ethereum’s slot time).
However, based sequencing still comes with tradeoffs, which is exactly why rollups typically implement their own sequencer:
- Fast preconfs – Rollup users don’t want to wait 12s+ for Ethereum blocks.
- Safe preconfs – Sometimes Ethereum blocks reorg, so users have to wait even longer to be safe, which again users don’t like. Sequencers can give preconfs which don’t depend on unfinalized Ethereum blocks and thus don’t need to reorg even if Ethereum itself experiences a short reorg.
- Efficient batch posting – Sequencers can batch a lot of data, compress it, and periodically post it to the BL in a cost-optimized manner (e.g., ensuring full blob usage).
Because of based sequencing, we need to post a blob every 12s and if there aren’t enough txs then we just won’t fill the blobs
Sadly it’s kinda expensive, so we really need based preconfs
— arixon.eth (@arixoneth) June 1, 2024
Based Rollups + Preconfs
So, can we have our cake and eat it too? Enter based preconfs.
We will explain the intuition behind based preconfs here relatively briefly so that we can compare BRs + preconfs vs. traditional rollups. Later on, we’ll come back to further analyze preconfs in greater detail more generally (i.e., both BR preconfs and BL preconfs on Ethereum L1 transactions).
The core idea is that BR preconfs must come from BL proposers. To provide preconfs, these proposers must put up some collateral (e.g., restaking) and opt into additional slashing conditions (i.e., that the preconfs they provide will indeed make it onchain as promised). Any proposer willing to do so can act as a BR sequencer and provide preconfs.
We should note that proposers (i.e., validators) are actually expected to delegate this role of providing preconfs to more specialized entities known as “gateways”. Giving out preconfs will require a relatively sophisticated entity, and Ethereum wants to keep proposers unsophisticated.
every time someone gets close to fully vertically integrating the transaction supply chain we will create an arbitrary new role to set them back 6 months. oh you’ve never heard of the pipeliner? he sits between the relay and the validator and increases decentralization
— woodchuck (@txsequencer) March 1, 2024
However, it’s expected that existing relays are going to take over this role too. The gateway would only interface between the user and the relay, so adding another independent entity only adds complexity and latency (though latency could also be addressed with co-location). The relay is already trusted by the builders and proposers, so we would be adding another trust requirement on them from the users here.
— Jon Charbonneau (@jon_charb) June 12, 2024
Note that while validators currently serve as Ethereum block proposers, there’s consideration for an upgrade by which the protocol itself would directly auction off proposal rights via execution auctions. This would allow sophisticated entities to purchase proposal rights directly, thus avoiding the need for validators (the current proposers) to delegate to them as contemplated here.
In any case, the important point is that any preconf faster than Ethereum’s consensus (12s) requires a trusted third party (TTP). Whether your TTP is a restaked validator, staked execution auction winner, delegated gateway, or whatever else – it fundamentally cannot provide real-time Ethereum security. Whether Coinbase is giving you a “based preconf” as an Ethereum proposer or a “traditional preconf” as a rollup sequencer – you’re trusting Coinbase. They similarly can put up a bond of some ETH, but in either case this is independent of the security of Ethereum’s consensus.

We should notice then that any based preconf design necessarily detracts from the stated goals of BRs we started with (simplicity and BL security). Based preconfs are increasingly complex, and they cannot provide the real-time security guarantees of Ethereum.
However, you should retain the ability to force a transaction directly via a BL transaction if these preconfers go offline or start censoring. These guarantees from Ethereum should get even stronger when inclusion lists are implemented.
For BRs – TTPs provide fast preconfs, and the BL provides eventual security.
Non-based Rollups + Based Fallback
Now let’s consider a traditional (i.e., non-based) rollup. Its own sequencer (whether centralized or decentralized) gives fast preconfs. Later, their users get full Ethereum security on a lag. This is inclusive of liveness (ledger growth + censorship resistance) which comes from some type of forced inclusion or BL fallback mechanism.
As I noted in Do Rollups Inherit Security?:
Rollups have the ability to expose confirmation rules with equivalent security properties as their host chain. They can receive these properties at best at the speed of their host chain consensus (and in practice it’s often a bit slower depending on how frequently the rollup posts to the host chain).
Rollups can also make available a “happy path” looser confirmation rule (i.e., sequencers) for better UX, but they retain the fallback in event of failure. If your sequencer halts, you can keep moving.
Note that the time to eventual security is the key variable to optimize here:
The assumption that rollup users can fall back to equivalent liveness as the host chain assumes that you can get forced inclusion at exactly the speed of the host chain blocks (e.g., if the rollup sequencer is censoring you, that you can force transaction inclusion in the next Ethereum block).
In practice, there is generally a short delay. If you allowed for immediate forced inclusion, you could expose profitable censorship MEV among other complexities. However, there are designs which may provide near real-time liveness guarantees from the host chain (e.g., perhaps at the speed of a few host chain blocks rather than one block).
In this spirit, Sovereign Labs has a design which does the following:
- Permissioned Sequencing – Rollups set a permissioned sequencer whose transactions are processed immediately upon their inclusion in the BL. Because they have a write-lock on the rollup’s state, they can provide reliable preconfs faster than the BL block time.
- Based Sequencing – Users can also submit transactions directly to their BL, but they are processed with an N block delay (where N is sufficiently small). This greatly reduces the “time to eventual security”, and in fact they even call the design “based sequencing with soft confirmations” because of that! (Note that this definition of BRs would conflict with the definition we provided earlier, i.e., that the BL proposer must have the right to sequence the BR or be delegated by them.)
For non-BRs – TTPs provide fast preconfs, and the BL provides eventual security.
y tho?
As we can see, both paths described above then produce the same effective result:
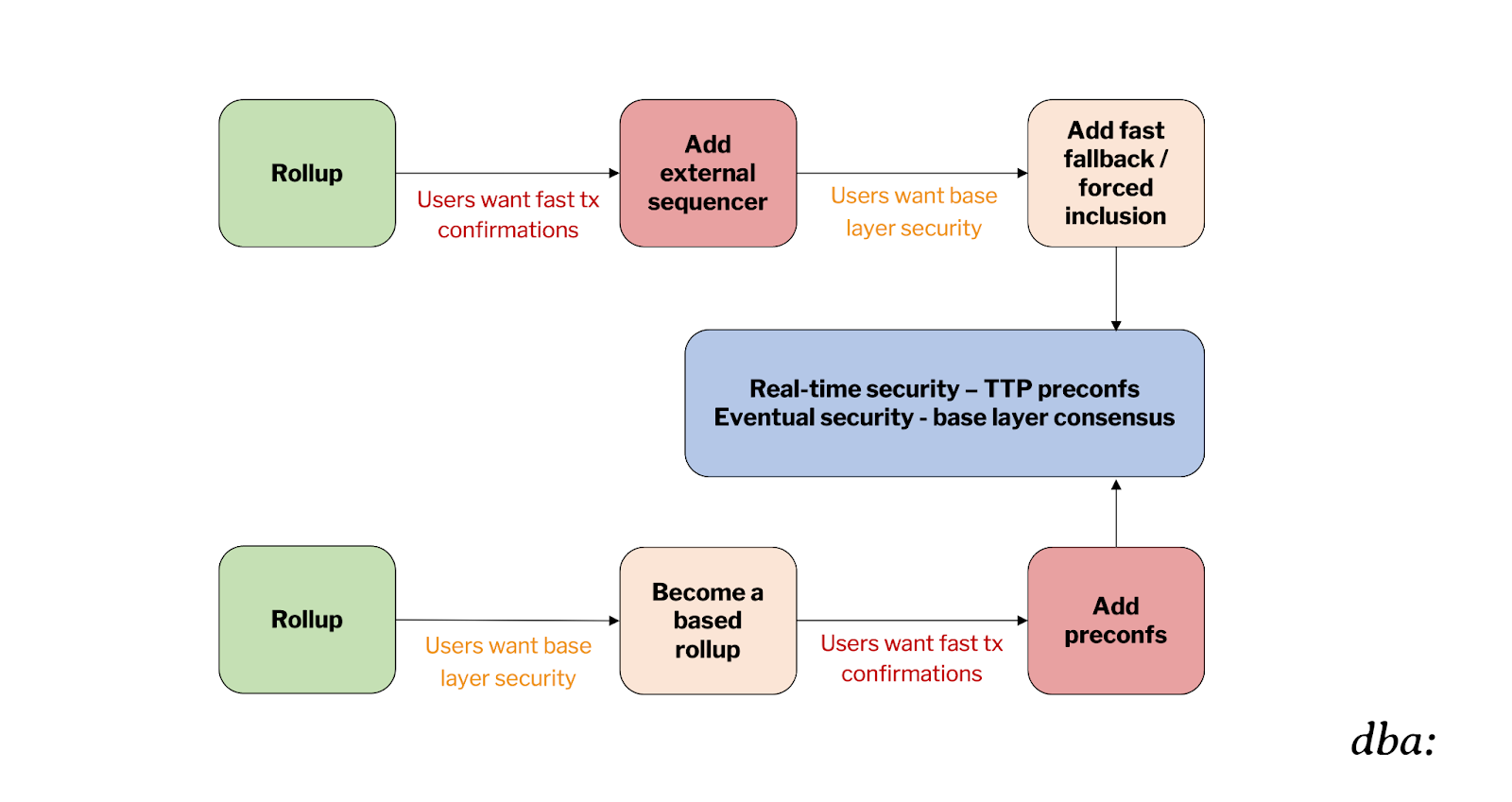
These BRs with preconfs no longer provide the simplicity or real-time security of Ethereum. So then what’s the point of all this now? Why don’t we just tighten up the fallbacks on “traditional” rollups? Wtf even is a “based rollup” at this point?

This actually comes back to my Proof of Governance post from last year where I discussed the fundamental use cases for Ethereum-specific restaking:
1) Technical (proposer commitments) – There’s no way around this – if you want a credible commitment to the ordering of an Ethereum block, it’s gotta come from Ethereum validators. MEV-Boost++ is one example of a hypothetical application that could fall into this bucket.
2) Social – I view Ethereum alignment as the primary use case for most restaking applications today, not pooling of economic security or decentralization. It’s getting to say “look we’re an Ethereum project!” It’s much the same reason why chains keep calling themselves Ethereum L2s regardless of the architecture.
We can modernize this in the context of asking what’s the value of a “BR + preconfs” over a “traditional rollup + fast fallback”?
1) Technical (proposer commitments) – Ethereum BRs with preconfs have one fundamental technical benefit – they can get a credible commitment from the current Ethereum proposer regarding the inclusion and ordering of the contents of an Ethereum block. This is potentially valuable for the same exact reasons we potentially want a bunch of rollups to share a sequencer. If the BL proposer is also the BR proposer (i.e, sequencer), then they can provide the same atomic inclusion guarantees with the BL as you can get between any rollups sharing the sequencer. They have a monopoly on both chains. Now, how valuable is this? We’ll come back to that in a bit.
2) Social (alignment / credible neutrality) – Love it or hate it, Ethereum alignment is a selling point to be a BR. I’m gonna be honest, I don’t know much of anything about Taiko beyond “they’re the BR guys,” and I probably wouldn’t know who they were if they weren’t the BR guys. Everyone wants some good co-marketing. There’s value to being the first-movers here, but I suspect this is not a lasting value prop and doesn’t carry over to many future potential BRs. Similarly, we all heard of the first handful of AVSs, but can you name all the current ones? I can’t.
At a higher level, you won’t get all the Ethereum rollups to opt into the (hypothetical) “Optimism shared sequencer” or the “Arbitrum shared sequencer”. You have a better shot though of getting them to all opt into the “Ethereum shared sequencer.” No new token, no new brand, no new consensus. If you think it’s valuable for all the Ethereum L2s to unite on sequencing, then this credible neutrality is potentially the strongest Schelling point to achieve that goal.
This credible neutrality is likely most valuable for rollups developers trying to attract cross-ecosystem users (e.g., applications with basic infrastructure like ENS). They may be hesitant to use the Optimism sequencer if it will alienate Arbitrum users, or vice versa.
We’ll cover each of these in more detail below.
Credible Neutrality
Going deeper on that social point, BRs are often seen as the maximally “Ethereum aligned” option. Putting aside anyone’s judgment of the value of this, the important point is that this presupposes a high degree of credible neutrality for any BR design.
A credibly neutral BR is easy to design in the vanilla case, but as we noted nobody really wants those. Preconfs then necessarily require the proposer to opt into additional slashing conditions. These additional slashing conditions require the proposer to use some additional system (e.g., potentially EigenLayer restaking, Symbiotic, or another standard) to make the commitment. A rollup may be happy opting into the credibly neutral “Ethereum sequencer” in the abstract, but credibly neutrality is likely lost if you’re using privately funded projects, perhaps even with tokens of their own.
There are several open questions regarding the collateral here:
Collateral Size
Early designs have assumed that the proposers would personally have to put up an incredibly high amount of collateral on the order of 1000 ETH. The issue is that fundamentally a proposer can always renege on their promise to delegate and self-build a block, equivocating on the preconfs. This can be incredibly valuable, and 1000 ETH is comfortably above the highest ever observed payments that have gone through MEV-Boost since its inception. The downside is that this of course necessarily creates a high barrier to entry for smaller proposers, while larger ones (e.g., Coinbase) could more reasonably put up 1000 ETH while earning rewards on all of their stake weight (>13% of total ETH staked) because registrants can put up a single bond for all of their validators. There are other ideas to allow for proposers with much smaller bonds, though of course come with tradeoffs. The design space here is just uncertain.
It’s worth noting that execution auctions would ease this concern, as we can assume that all proposers would then be sophisticated actors easily capable of this.

Source: Barnabé Monnot, From MEV-Boost to ePBS to APS
However, even the large operators are hesitant to put up large amounts, because of potential liveness issues resulting in slashing (a liveness failure on an operator’s part, giving our preconfs then going down before they get them included in a block, is a safety failure all the same to users, and needs to be penalized harshly).
Collateral Type
Vanilla ETH is likely the only credibly neutral collateral in this situation. However, there will naturally be a desire to use more capital efficient assets (e.g., stETH). There are some ideas to have an underwriter handle this conversion, as described by mteam here.
Platform
It wouldn’t be very “credibly neutral” if the “Ethereum based preconfs” are more like the “EigenLayer based preconfs” or the “Symbiotic based preconfs.” There are teams that are planning to go in this direction, but it’s not a strict requirement to use such a platform. It’s possible to create a general and neutral standard for everyone to use, and such a system would seem better positioned for general adoption as the most based option.
Adoption of public good standards will be needed for based preconf designs to plausibly be “credibly neutral.”
Preconfirmations
Inclusion vs. State Preconfs
We will now cover preconfs in greater detail. While we discussed a specific type of preconf earlier (BR preconfs on state), we must note that they are a fully general concept. You can offer preconfs on BL transactions in addition to BRs, and you can offer different strengths of preconfs:
- Inclusion Preconfs – A weaker commitment that a transaction will eventually be included onchain.
- State Preconfs – The strongest commitment that a transaction will eventually be included onchain and a guarantee of the resulting state.
The latter (state preconfs) is of course what users want their wallets to show them:
I swapped 1 ETH for $4000 USDC and paid 0.0001 ETH in fees
Not inclusion preconfs:
My transaction attempting to swap 1 ETH for $4000 USDC and pay up to 0.0001 ETH in fees will eventually land onchain, but maybe it succeeds, maybe it fails, we’ll see
However, we should note that inclusion preconfs are effectively interchangeable with state preconfs in the case of user actions taken on non-contentious state (e.g., simple transfers where only the user themself could invalidate the transaction). In this case, a promise that for example “Alice’s USDC transfer to Bob will be included in the next few blocks” is good enough for a wallet to just show the user “you’ve sent your USDC to Bob.”
Unsurprisingly, the stronger commitments (state preconfs) are harder to get. Fundamentally, they require a credible commitment from the entity who currently has a monopoly on proposing blocks (i.e., a write-lock on chain state). In the case of Ethereum L1 preconfs, this is always the current Ethereum L1 proposer. In the case of BR preconfs, this is presumably the next Ethereum L1 proposer in the BR’s lookahead (thus making them the current proposer for the BR), as we will see below. Proposer and sequencer are generally interchangeable terms, with the former more often used in the L1 context and the latter in the L2 context.
Pricing Preconfs
Another big distinction we need to make is what type of state are these preconfs touching:
- Non-contentious state – Nobody else needs access to this state (e.g., Alice wants to transfer USDC to Bob)
- Contentious state – Others want access to this state (e.g., swaps in an ETH/USDC AMM pool)
Preconfs are constraints on what block may ultimately be produced. All else equal, constraining the search space for builders inherently can only reduce the potential value they may capture from ordering it. That means less value would be returned to the proposer. To make it incentive compatible, the gateway needs to charge a preconf fee ≥ the potential MEV lost from constraining the outcome.
This is simple enough when the MEV lost is ~0 (e.g., as in a USDC transfer). In this scenario, charging some nominal flat fee could be reasonable. But we have a big problem – how do we price preconfs on contentious state? Pricing preconfs ahead-of-time vs. just-in-time seems like it would pay less. All else equal, it is most profitable for a builder to wait until the last second possible to capture and accurately price the MEV.
Here is the fundamental problem I see with preconf pricing.
Read the screenshot below. Let’s say there is an arb opportunity 6s into the slot. Call this event “X.” If this opportunity is taken right away, the arbitrageur makes p1(X).
In the remaining 6s, there may arise… pic.twitter.com/MjOzZTqxJa
— Alex Nezlobin (@0x94305) June 17, 2024
Let’s assume though that there’s sufficient user demand for fast preconfs on contentious state though (considering both sophisticated searchers and normie users), such that there will at times be a clearing price that’s beneficial for everyone. Now, how exactly do you price a preconf for a transaction on a piece of contentious state that you could otherwise include at any point in the next 12 seconds, potentially foregoing more profitable opportunities that would no longer be possible?
Preconfs on contested state being streamed throughout the block would conflict with how builders create blocks. Pricing preconfs accurately requires estimating in real-time the MEV impact of including it now rather than delaying it, which means executing and simulating the possible outcomes. That means the gateway now needs to be a highly sophisticated searcher/builder.
We already assumed the gateway and relay would merge. If they need to continuously price preconfs, then they’ll also merge with the builder. We also accepted that USC would accelerate merging the builder and the prover. It also seems like execution auctions will sell proposer rights directly to sophisticated actors (likely builders) able to price them.
This puts the entirety of the Ethereum L1 and BR transaction supply chain into one box that has a monopoly write-lock on the state of all chains for that period.

The ordering policies of the preconf service are unclear (e.g., do they always run FCFS or order them in another manner). It’s also potentially possible for the gateway to run an auction over all preconfs (e.g., allowing searchers to bid on preconfs), though it’s not clear what such a design would look like, and it would necessarily mean higher latency.
Fair Exchange Problem
There’s a fair exchange problem with preconfs where the gateway isn’t actually directly incentivized to release the preconf.
Consider the following example:
- The current gateway has a 12s monopoly
- A user submits a preconf transaction request right at the start of the slot (t = 0)
- The gateway waits until t = 11.5 to release all preconfs they made during their slot, leaving a 500ms buffer to get them all in with their block. At that time, they can decide which preconfs to include if they are profitable, and which to exclude.
In this scenario, the user can end up paying for the preconf even though they don’t actually receive it until the end of the slot. The gateway could also just drop it at the end of the slot if they decide it wasn’t profitable to include. This withholding by the gateway is not an objectively attributable fault (but it could be intersubjectively attributable).
In fact, there’s actually an incentive for gateways to withhold the preconfs until the end. Where there’s information asymmetry, there’s MEV. Keeping transactions private would allow a builder to have a more up to date view of the state of the world, allowing them to better price risk and capture MEV. There is no consensus over the set of preconfs being given to users, so the gateway cannot be held accountable here.
There would need to be standards in place and expectations for the preconfirmer to immediately publicly gossip all preconfs. This would give users what they want immediately and allow others to see that a gateway is providing the expected services. If they fail to do so in the future, then users wouldn’t trust them and pay them for preconfs. The reputation of the gateway has value. That being said, it can also be extremely valuable to be dishonest here and go back against preconfs.
L1 Base Layer Preconfs
With the general preconf points out of the way, we’ll now discuss the nuances of L1 preconfs. While we didn’t mention them earlier, there are projects building these, and their interaction with BR preconfs will be important.
For example, Bolt is one such protocol which wants to enable Ethereum proposers to make credible commitments about their block contents. Registered proposers can run the Bolt sidecar to receive preconf requests from users, confirm them, then send this information to relays and builders who can return blocks which respect these constraints (i.e., so they return a block which includes the transactions which the proposer gave preconfs to).
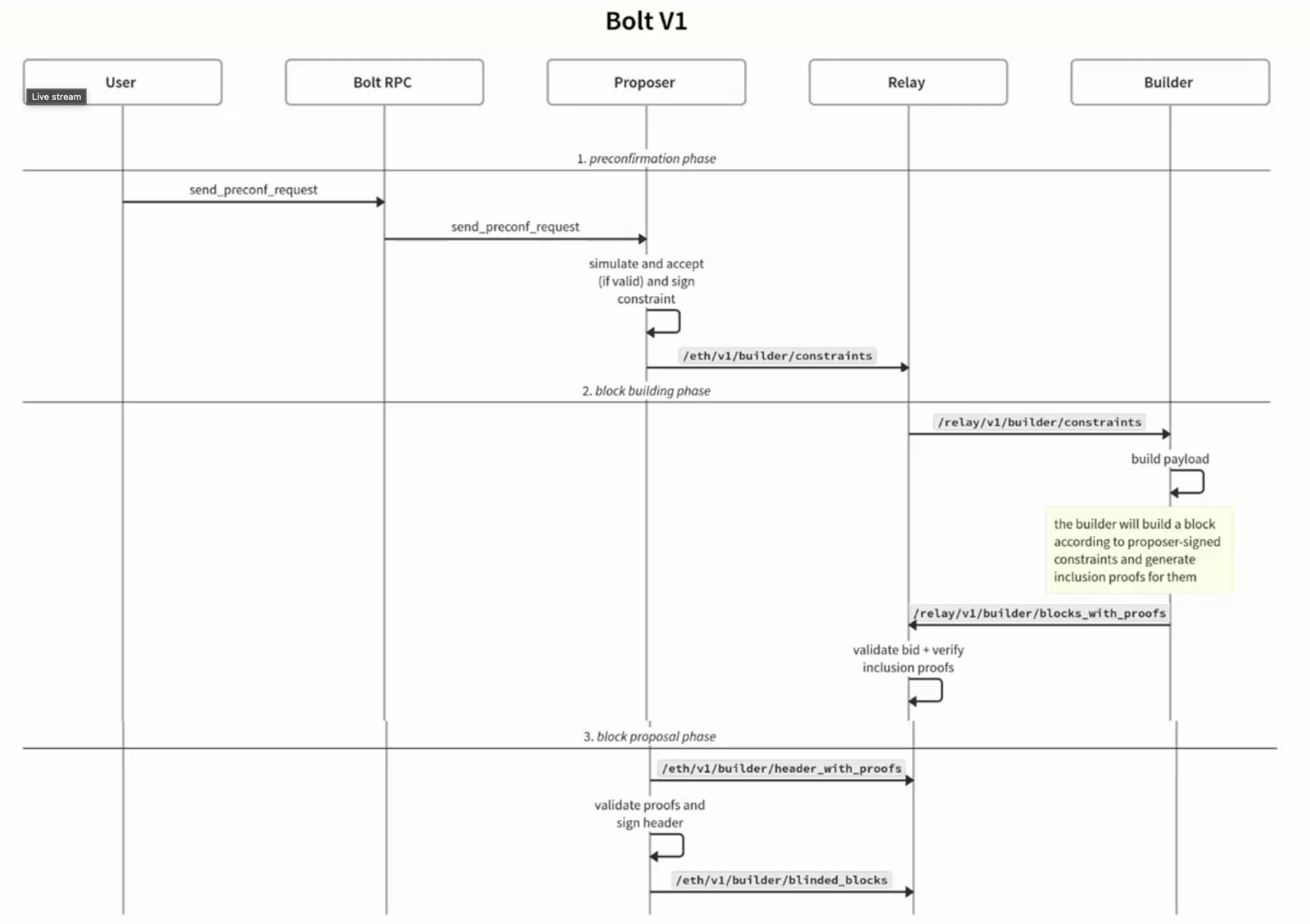
It’s important to note here that Bolt v1 described here only supports simple transaction inclusion preconfs for non-contentious state where only the user can invalidate the preconf. As we discussed earlier, these are the simplest and weakest commitments to provide.
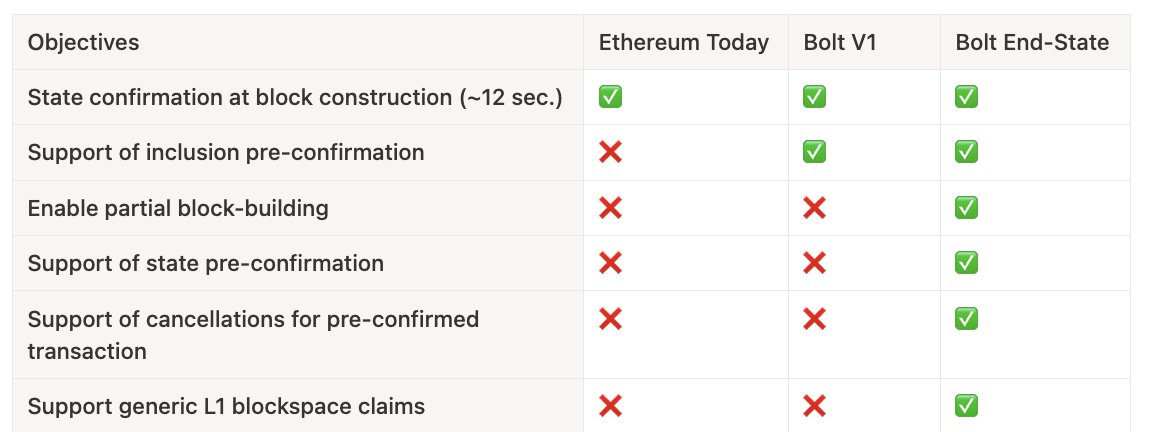
All of these preconf teams have bigger ambitions (e.g., state preconfs, partial-block auctions, slot or partial-slot auctions), so what’s holding them back?
- Accountability – Commitment breaches should be provable onchain for objective slashing. It’s relatively easy to prove transaction inclusion, but it’s not as clear how to enforce other commitments such as slot auctions.
- Capital requirements – Providing arbitrary commitments means that the value of breaching a commitment could be arbitrarily high. Gateways will likely end up needing to stake huge amounts (e.g., thousands of ETH) to provide these. These may very well end up being pooled, benefiting the largest entities (e.g., large trading firms or Coinbase) and leaving out smaller entities.
- Pricing – There are a lot of open questions around how to price something like continuously streamed state preconfs even if we decide it’s feasible and valuable.
- Network Participation – This is perhaps the most important and fundamental point. As we mentioned, only the current proposer who has a write-lock on state can provide commitments like state preconfs. In theory, 100% of proposers could opt into this system and mimic this. In practice, that won’t happen.
MEV-Boost, a simpler product with years of track record that’s incredibly profitable to run, has >92% participation for context (likely even a bit higher as this doesn’t account for min-bid). A new preconf service would certainly get a far lower participation rate. But even if it could get up into the ~90% range, this doesn’t seem like a useful product for normal users. You can’t tell users 10% of the time “oh sorry no preconfs available right now, check back in a bit.”
At best this feels like state preconfs would only be an optional tool for sophisticated searchers and traders who may want to get a commitment earlier in the block when that slot happens to have a proposer opted in. That may be valuable, but there’s no fragmentation or UX unlocks here.
L2 Based Rollup Preconfs
BR preconfs must come from the BL proposers (that’s why they’re “based”). This requires them to stake some collateral and opt into additional slashing conditions (i.e., that the preconfs they provide will indeed make it onchain as promised). Any proposer willing to do so can act as a BR sequencer and provide preconfs.
Importantly, these BR preconfs are state preconfs not just inclusion peconfs. This is possible because BRs are opting into a design where they give a rotating sequencer monopoly to BL proposers that sign up to be gateways.
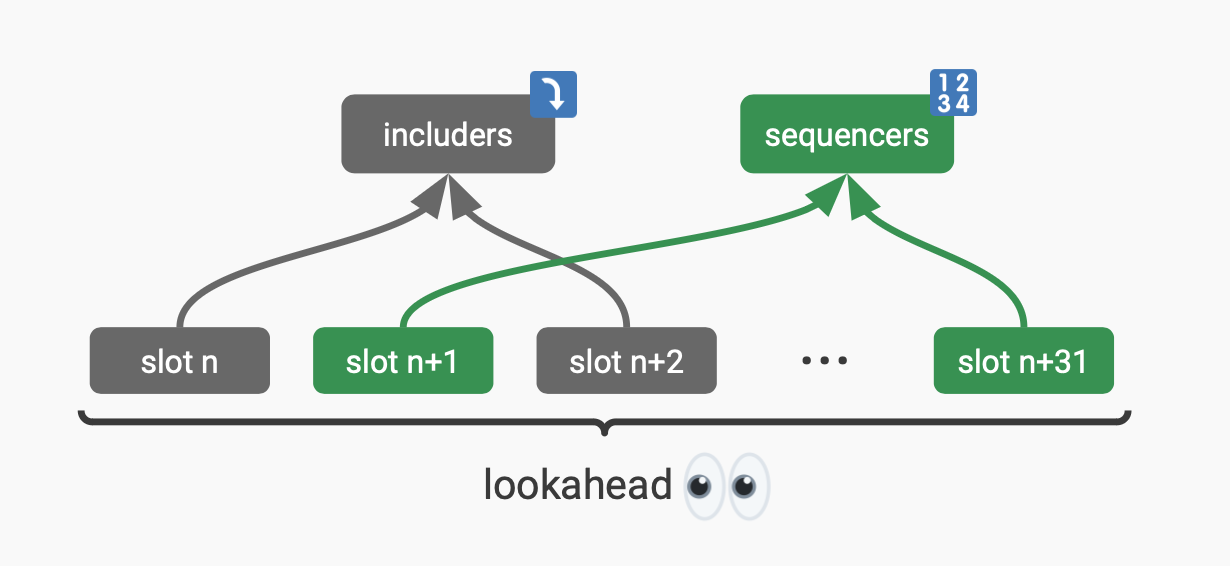
Today, one Ethereum validator serves as the proposer for each slot, and the proposer schedule is always known for the current epoch and the following one. An epoch is 32 slots, so we always know the next 32-64 proposers at a given time. The design works by granting the next active sequencer (i.e., the next sequencer in the lookahead) monopoly powers to sequence transactions for the BRs opted into this preconf system. Gateways must sign to advance the state of the BR chains.
Note that every proposer (even ones who haven’t opted into being a gateway) has the right but not the obligation to include transactions which have been given preconfs by the sequencers (i.e., those proposers who have opted into being a gateway). They may act as an includer so long as they have the full list of transactions which have been preconfirmed leading up to that time (the sequencer can create a BL blob that has the BR transactions and gossip them).
Source: Ethereum sequencing, Justin Drake
The transaction flow works as follows:
- BR user submits their transaction to the next sequencer in the lookahead (slot n+1 proposer in the image below)
- The sequencer immediately provides a preconfirm for the resulting state (e.g., user swapped 1 ETH for $4000 USDC on the BR and paid 0.0001 ETH in fees)
- At this point, any includer may include the sequenced transaction (the slot n proposer does so in the image below)
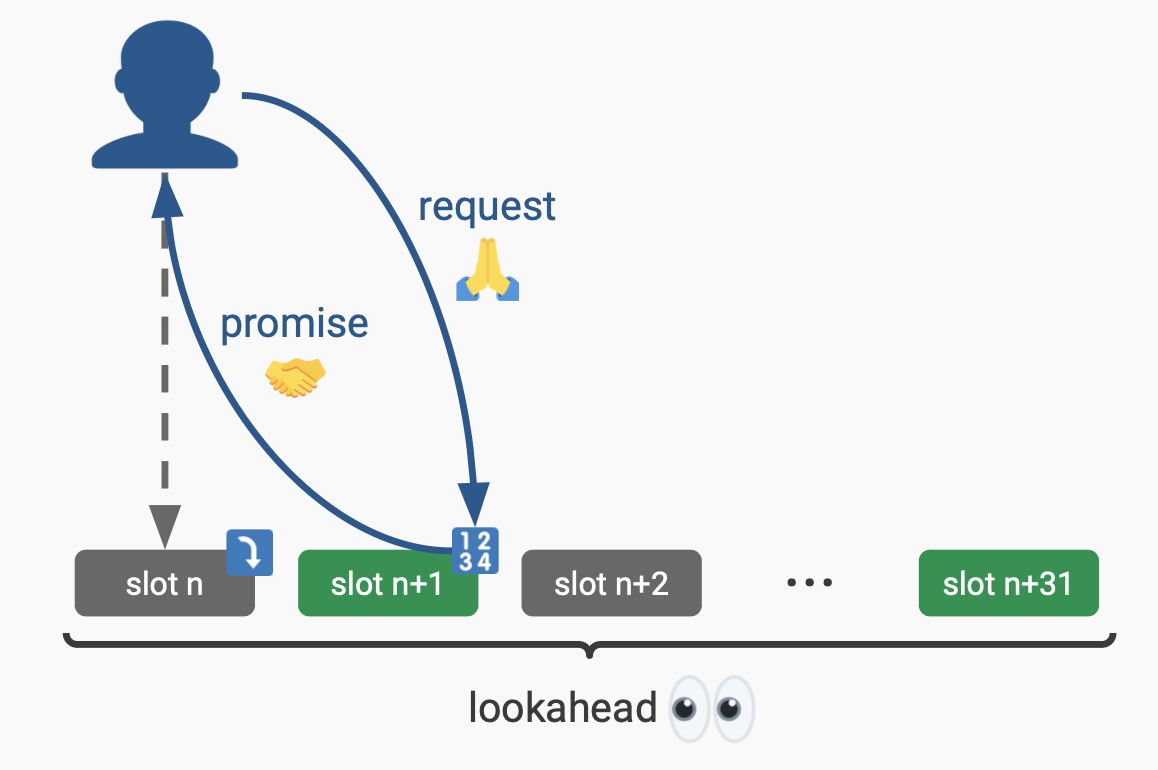
Source: Ethereum sequencing, Justin Drake
If the other includers do not include the preconfs, then the sequencer who gave them can simply include them onchain when it’s their turn as the BL proposer. For example, in the image above let’s say the slot n includer decided not to include the preconfs that the slot n+1 sequencer gave out. Then the slot n+1 sequencer would be responsible for including all preconfs that it gave out during slot n and slot n+1 when it submits its BL block for n+1. This allows the sequencer to confidently give out preconfs for the full period between them and whoever the last sequencer was.
To simplify the explanations above, we just assumed the L1 proposer would fulfill this preconfer role. As described earlier though, this is not likely to be the case. It will require a sophisticated entity to price the preconfs, run full nodes for all BRs, have DoS protection and sufficient bandwidth for all BR transactions, etc. Ethereum wants to keep validators very unsophisticated, so proposers will presumably outsource preconfs to another entity in very much the same way they outsource full L1 block production via MEV-Boost today.
Proposers can delegate to gateways via either onchain or offchain mechanisms, and this can be done all the way up until just before their slot. As noted earlier, this role is likely in practice to be taken over by relays. It’s also possible that they would need to merge with builders as well.
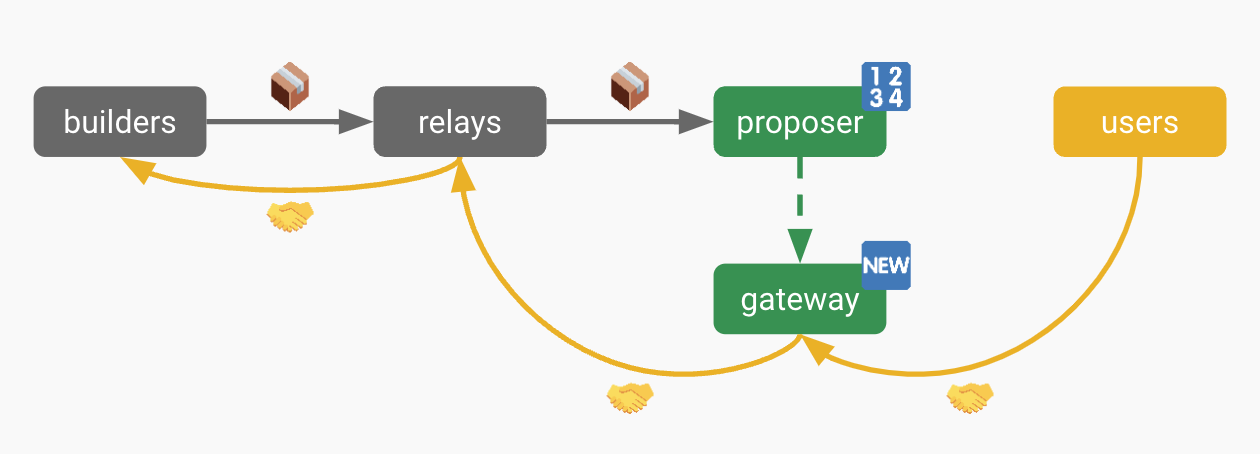
Source: Based sequencing, Justin Drake
As described earlier, only one entity can be delegated to be the gateway at a given time. This is required to provide reliable state preconfs. UIs (e.g., wallets like MetaMask) would look out for who the next gateway is, and they’d send user transactions there.
Ethereum Rollups – How Based Will They Be?
With sufficient background now in place – should Ethereum rollups be based? There are really two embedded questions here:
- Should many Ethereum rollups share a sequencer?
- If yes, should it be a based sequencer (i.e., involving the Ethereum BL proposers and surrounding MEV infrastructure)?
First, it’s important to note that you can share a sequencer with other chains on an ad-hoc basis. For example, the Ethereum proposer may sequence one block for you if they bid the highest, then some other BFT consensus could sequence your next block if they bid the highest. However, this still requires a chain to fully opt into this uniform shared auction that can run synchronously with these other chains, so there still exist tradeoffs regarding control and flexibility (e.g., shared block times). It’s just that the winning sequencer entity can shift.
Regardless, let’s just assume condition 1 is met. I think we have compelling evidence at this point that there exists sufficient demand to use a decentralized shared sequencer. Even if they care less about the “shared aspect”, I think there’s an incredibly high value in being able to purchase a decentralized sequencer-as-a-service off the shelf (in fact I think this is the biggest value here).
That said, I think @evansforbes’s proposal to apply the idea to shared sequencing does have a shot because it also solves an infra overhead + regulatory problem for rollup devs. https://t.co/KaDpCpyasc
— Sam Hart (@hxrts) March 10, 2024
Now, should this shared sequencer be an Ethereum based sequencer?
Technical (Proposer Commitments)
I do not see a strong technical argument for using an Ethereum based sequencer. Any interoperability between BRs and the Ethereum L1 would be incredibly limited due to inability to reliably execute against the L1 (i.e., not consistently having a write-lock on L1 state), long block times (12s), and the fact that BR transactions that did wish to interact with the L1 would then have to reorg alongside it. There’s no free lunch here. This doesn’t unlock any valuable user-facing products vs. any other external shared sequencer.
The primary value I see is that adding the Ethereum L1 into this larger combinatorial auction may result in higher aggregate value created and allow the L1 to capture more value. Taking this logic to the extreme, we should probably put everything in the world in the same auction. This universal auction should also be sequencing Taylor Swift concert tickets. I’m not quite there.
This is just to highlight that there is real technical and social complexity of creating and opting everyone into this shared auction which has a real cost, which in my mind likely outweighs any theoretical additional value created here. You can easily build a far better technical design to run this from first principles if we’re not trying to strap it on top of Ethereum L1 (e.g., just have a simple fast consensus mechanism built for this purpose). Not to mention the fact that such a combinatorial auction would create an exponential blowup in complexity.
In practice, there exists some meaningful risk to me that this may actually be severely counterproductive for Ethereum, as this based preconf architecture seems potentially accelerationist regarding MEV infrastructure when Ethereum’s supply chain is already somewhat brittle. This risks jeopardizing the network’s decentralization and censorship resistance – the very things that make it valuable to begin with.
Social (Credible Neutrality)
I do see a valid social argument for an Ethereum based sequencer.
As noted earlier, it’s no doubt that “alignment” is a sell for the initial BRs. That’s fine, but I don’t think this lasts. It’s cool to be the first BR, it’s not cool to be the 8th. There needs to be some other value add.
I think that the credible neutrality of an Ethereum based sequencer is potentially that value. It’s likely the strongest argument in favor of such a design at least. There are a lot of chains that want to get a decentralized sequencer off-the-shelf. If we can eventually design enough infrastructure on top of this thing that it improves cross-chain UX, then even better. Of the projects that want such a design though, I imagine a lot of them are hesitant to “pick sides” with any third-party protocol. As noted earlier, imagine you’re an app-chain with some basic general infrastructure like ENS, and you want a rollup. You don’t want to pick the (hypothetical) Arbitrum shared sequencer and turn off the Optimism crowd, or vice versa.
Possibly the only solution to the social coordination problem here is to have a credibly neutral shared sequencer, which Ethereum is clearly the strongest candidate for. Note that this places an even higher degree of emphasis on the points I made earlier regarding credible neutrality – if this is the primary value-add of such a service, then that must be an incredibly high-priority design goal in creating it. It won’t work if it has the appearance of being the pet project of some third-party protocol with its own profit motives. It has to actually be the Ethereum shared sequencer.
It’s worth noting that there’s also reasonable criticism that “neutral” here is code for “Ethereum.” That is to say, that its primary motivation is to benefit Ethereum and its native surrounding infrastructure. And of course such a system would benefit these parties. It would mean more value capture to ETH the asset, and more profitability for Ethereum builders, relays, and searchers.
Fast Based Rollups
Fast Base Layers
We should now understand that you can have BRs on a slow BL like Ethereum, you can add trusted preconfs for faster UX, and you can even ensure safety when moving across chains via cryptoeconomic or cryptographic guarantees.
As noted though, what if we just designed this thing from scratch. No dealing with the tech debt and decisions of an existing chain. What’s the obvious way to build the thing…
no more questions like this
— Jon Charbonneau (@jon_charb) June 11, 2024
Earlier, we discussed how the only technical reason to be a BR with preconfs for a given BL (e.g., Ethereum) is so that its proposer may provide credible commitments at times regarding synchronous atomic inclusion with the BL.
However, we didn’t seriously discuss the ability to be a BR without preconfs. We basically threw this out the window because Ethereum is slow and users are impatient.
So why don’t we just use a fast BL for BRs?
This solves pretty much all of the complex edge cases and concerns we had before. We don’t want weird edge cases where gateways have liveness failures (which have the same result as safety failures here), we don’t want them to back out of promised preconfs (i.e., safety failures), and we don’t want Ethereum reorgs. This is exactly why consensus exists.
DA Layers are Dead, Long Live Sequencing Layers!
Most of the conversation regarding lazy sequencers contemplates them as a rollup sequencer which then dumps its data on some other DA layer. For example, Astria’s first two rollups (Forma and Flame) will use Celestia as their DA layer. Astria’s consensus will sequence these rollups, then it will relay their data to Celestia.
This combination is an especially nice one because they’re obvious complements – Astria provides all of the sequencing infrastructure and Celestia provides trust-minimized verification via data availability sampling (DAS).
However, Astria could similarly be used to sequence a rollup that’s native to Ethereum, Bitcoin, Solana, or whatever else you want. For example, it could even be set up to be used as a preconfer for Ethereum “BRs with preconfs” (e.g., instead of a centralized gateway, as a lazy sequencer is basically just an incentivized and decentralized relay).
To be clear though, every chain is a DA layer. Full nodes can always check for DA. It’s a part of any chain’s validity conditions that the data is available, so consensus is always signing off that the data is available. Light nodes checking for their sign-off get an honest majority assumption. The only difference is if the chain provides another option for light clients to sample directly for DA rather than asking the consensus.

Every chain is a DA layer
Celestia should be called a DAS layer instead of a DA layer pic.twitter.com/9bCVElZHiJ
— Jon Charbonneau (@jon_charb) April 13, 2024
However, as I noted in Do Rollups Inherit Security?, fast chains like Astria could technically add a slow path for DAS (to improve verifiability), and slow chains like Celestia could add a fast path for sequencing (with a majority trust assumption and no DAS), so-called “fast blocks slow squares.”
Moving to vertically integrate specialized layers like sequencing or DAS would further narrow distinction between modular vs. integrated blockchains. This applies similarly for vertical integration of the settlement layer via adding ZK verifier accounts to Celestia’s base layer.
Manlets getting L2 curious while Celestia looking how to integrate ZK verification and fast blocks to become a settlement and sequencing layer pic.twitter.com/v3dTqFEpK0
— Jon Charbonneau (@jon_charb) March 20, 2024
However, there’s meaningful value in keeping these services separate rather than bundling them. This is the modular approach which allows rollups to pick which features they want off the shelf (e.g., I want to buy decentralized sequencing with fast blocks, but I don’t want to pay for DAS, or vice versa). Researchers have shown they want DAS, but users so far have shown they just want fast blocks.
Bundling services as in the “fast blocks slow squares” would be very opinionated and integrated. This would necessarily add complexity and cost. The effect of slot length on timing games (and thus decentralization potentially) which are now pervasive on Ethereum is also a consideration.
Fast Base Layer vs. Slow + Preconfs
But you can also just use Astria as the BL for rollups. Shared sequencers can be thought of as BLs that are optimized for BRs of their own.
When your BL is fast, your BR doesn’t need preconfs because it just gets fast confirmations out of the box! Then your rollup actually gets the real-time security of your BL, unlike BRs + preconfs which necessarily lose this.
BRs without preconfs are in fact the most logical way to build a rollup. That’s why today’s rollups all started there:
I was a guy at the time yelling about “rollups don’t / can’t give you fast txs!” but then everyone was associating sequencers w/ rollups, and then we started using a sequencer, so I kinda just gave up and moved on. But now that it’s “based” again, I might resume my bikeshedding.
— Daniel “peq umop” Goldman (@DZack23) March 14, 2023

It’s clear that a BL with fast blocks fixes most of our problems in “based rollups + preconfs.” Shared sequencers are naturally built more from a first principles approach of “hey app developers just want to launch a fast, reliable, and decentralized chain – how do I give that to them?” Trying to add preconfs after the fact onto a slower base layer like Ethereum results in the complexities we’ve described above.

We’re All Building the Same Thing
Modularity is Inevitable
So, we saw how we can aggregate modular chains back together, providing universal synchronous composability (USC). There are tradeoffs of course, but they do reintroduce a meaningful degree of unity while preserving far more flexibility than using a single state machine. There’s also a very compelling case to me that asynchronous composability is all we need for the vast majority of use cases. We need low-latency, performance, and good UX. The internet is asynchronous and it works pretty damn great abstracting that all away. Composability is a huge value add of crypto, but composability ≠ synchrony.
Flexibility and sovereignty benefits aside, most people would agree we’ll eventually need many chains for scale anyway. This means we’ll end up with many systems that we need to unify, so the modular direction is inevitable here.
Ethereum + Preconfs → Solana?
Now, let’s compare the endgames here. In particular we’ll compare the Solana endgame vs. Ethereum’s endgame if it goes down this road of maximizing unity and UX with based rollups + preconfs.
In this vision, we have a bunch of these BRs using the Ethereum based sequencer. Gateways are continuously streaming proposer-promised (i.e., without any consensus weight) preconfs to users at low latency, then Ethereum proposers commit them into a full block every once in a while. This may sound familiar because that’s pretty much what we described for Solana earlier with shred streaming!
many such caseshttps://t.co/VuZ4whwjJZ pic.twitter.com/CHVqEJoVU9
— Jon Charbonneau (@jon_charb) June 12, 2024
So, is this just a more complicated Solana? The big difference here is in slot times:

Ethereum trying to add this on top of a slow chain clearly presents issues at first glance:
- Ethereum’s consensus is way too slow for users, so the only way to get a credibly neutral fast UX is with proposer-promised preconfs on an opt-in basis. Its primary bottleneck today is signature aggregation as a result of its huge validator set size (MaxEB and improved signature aggregation could help here).
- This results in much longer proposer monopolies, providing higher incentives and freedom to capture more MEV by acting dishonestly (e.g., withholding preconfs).
- If gateways do start to delay or withhold preconfs, then the worst case for users falls back to being dependent on Ethereum slot times. Even if Solana block producers stopped continuous block building and streaming within their allocated monopolies (as it is likely rational for them to do to some degree for the same exact reason), then the worst case falls back to reliance on a quickly rotating consensus. The four-slot monopoly today is needed though for network reliability.
- In practice there are likely to be incredibly few gateways, at least to start, yielding a more centralized operator set vs. chains like Solana.
- Potentially incredibly high collateral requirements for proposers (noting design space is still a work in progress).
- Concerns over liveness issues being incredibly costly here (as operator liveness issues leading to dropped preconfs amount to safety failures for users, and thus must be heavily slashable).
All of this is solved with a fast consensus. All these systems are literally why we make BFT systems in the first place. So why shouldn’t Ethereum just make its consensus go faster then? Are there some less obvious tradeoffs with having super low-latency base layer block times?
Yeah because I have better things to do than write a fucking essay about how shorter blocktimes are good. We all know it’s true. I don’t feel the need to waste everyone’s time on here by writing a 20 page think piece about it to farm clout. https://t.co/M52twdysOK
— Max Resnick (@MaxResnick1) June 16, 2024
Luckily I have nothing better to do than write an essay about whether shorter blocktimes are good. The big concern with shorter slot times relates to validator and operator centralization. Specifically, there are concerns regarding the interaction of short slot times with timing games:
1/ Time is Money: Timing Games in PoS Protocolshttps://t.co/F0fY9WmBLY
tldr: a block proposer may strategically delay their block proposal to maximize MEV capture, while making sure the block is still early enough to become part of the canonical chain.
— caspar (@casparschwa) May 23, 2023
We see timing games progressing on Ethereum already. Proposers are proposing blocks later in their slots, making more money at the expense of others. Relays are also offering “timing games as a service” whereby they similarly delay blocks later in the slot:
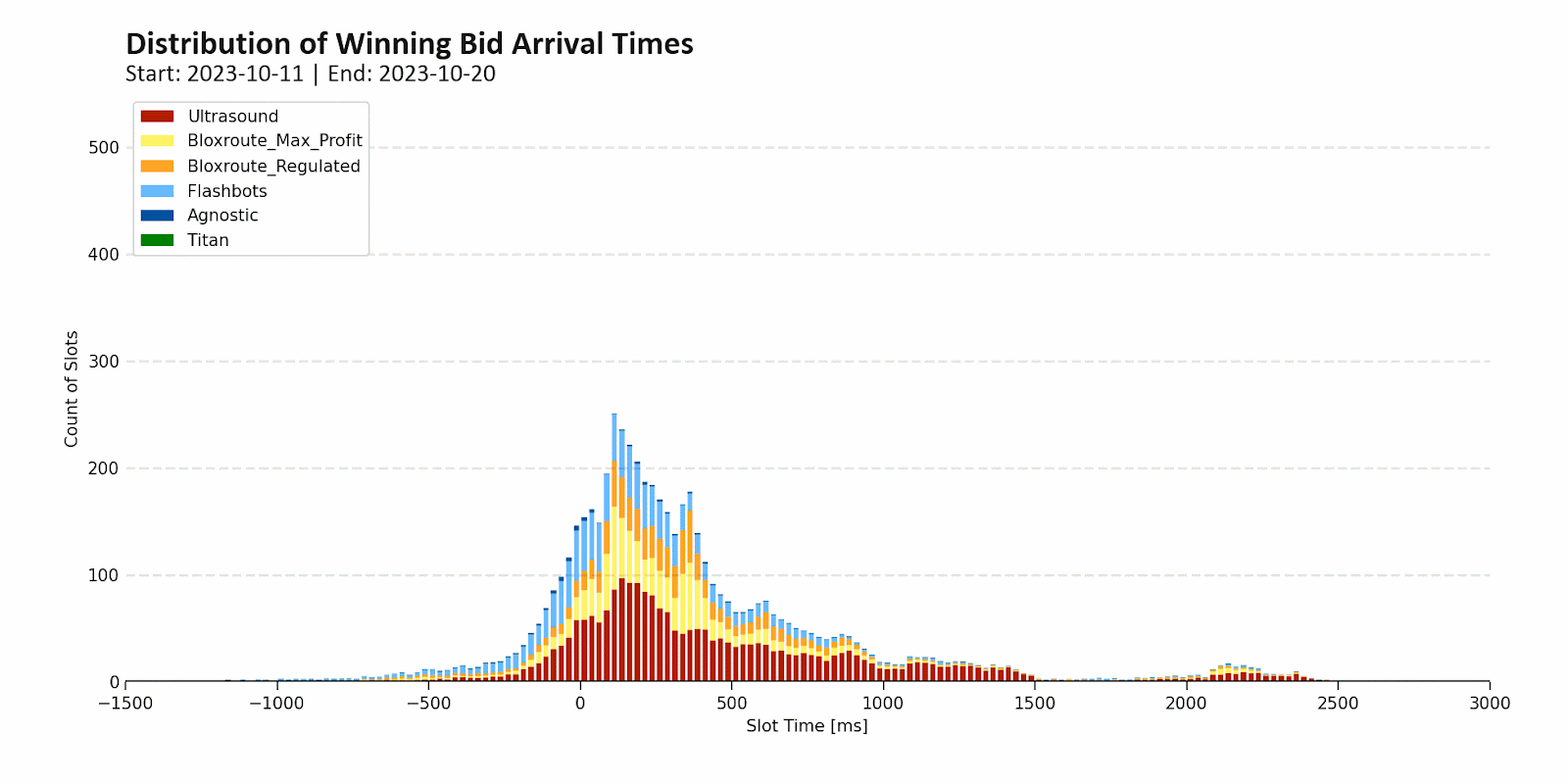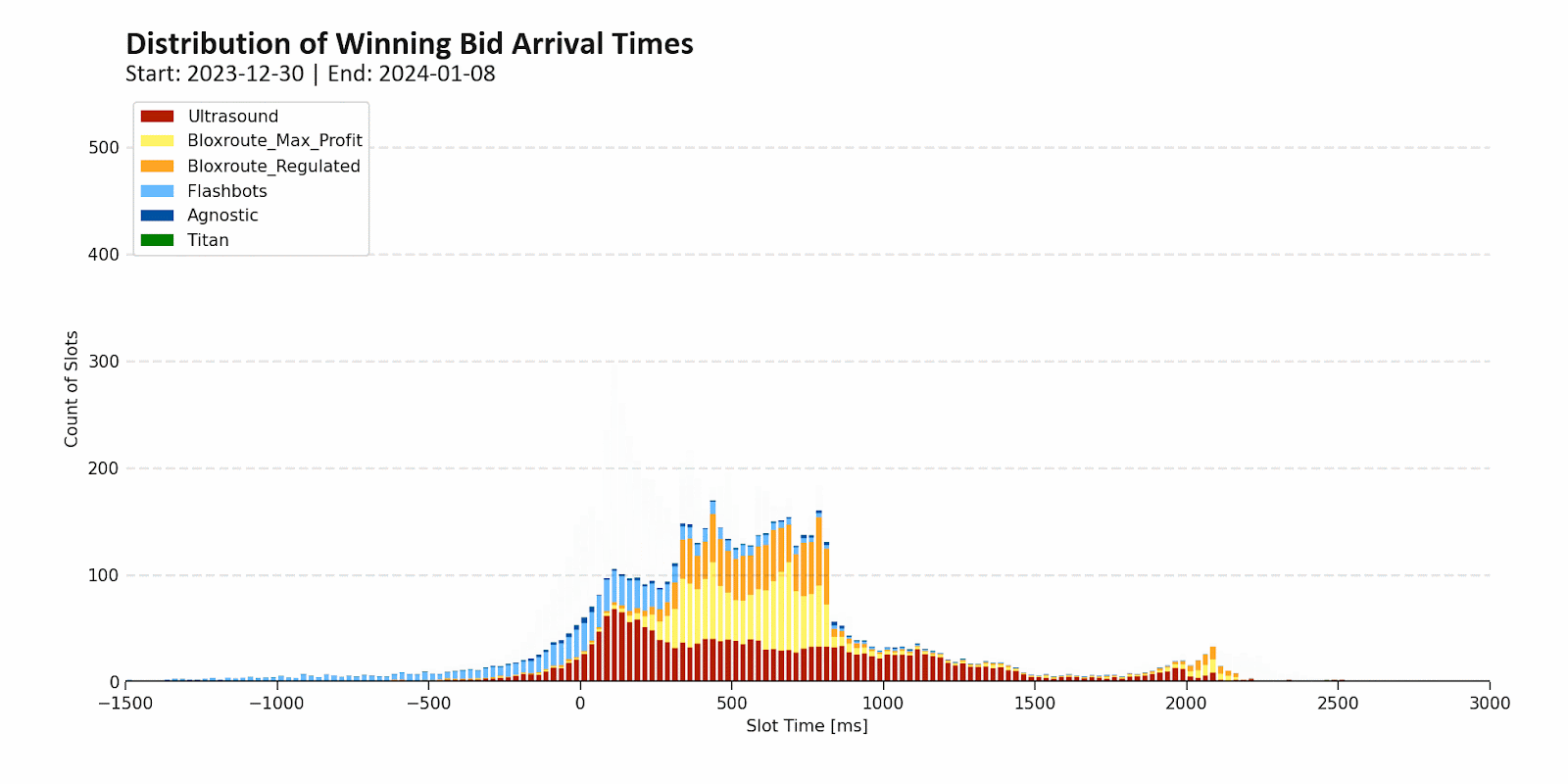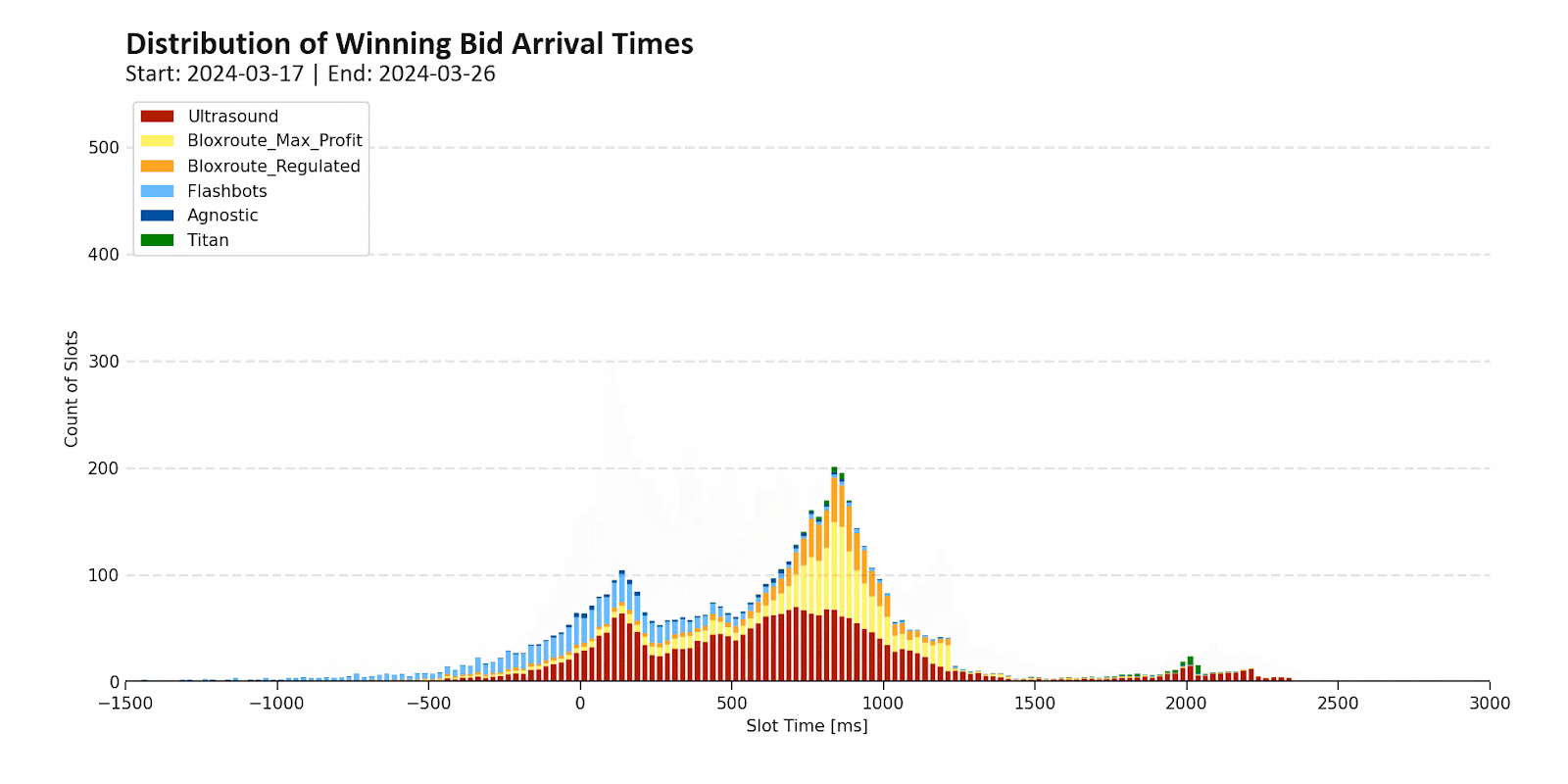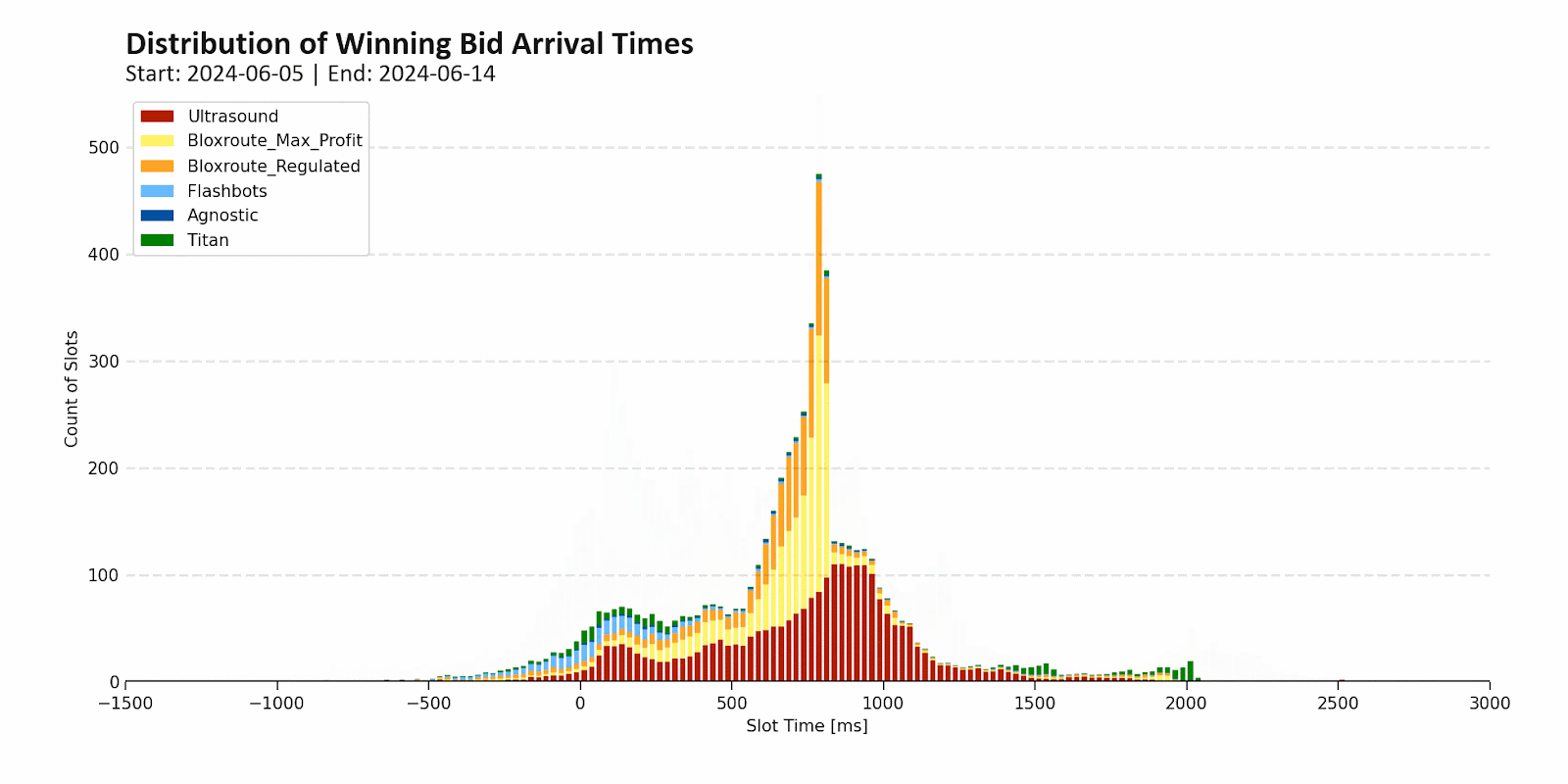
Source: Data Always
Timing games were a huge topic of discussion on the somewhat infamous Justin vs. Toly Bankless podcast from a few weeks back:
Eg let’s say you’re 100ms faster than everyone else
If you have 1s slots, you can make 10% more than everyone else
If you have 10s slots, you can make 1% more than everyone else
— Jon Charbonneau (@jon_charb) June 4, 2024
Justin mostly argued that timing games will be an issue, and the incremental rewards will always be relevant. Toly mostly argued that timing games won’t be an issue, and that the incremental rewards earned from additional MEV extraction aren’t enough to be concerned about.
I personally find it difficult to ignore the importance of timing games here:
- We already see them in practice on Ethereum today. The Solana argument is that this happens only because MEV became socially normalized in Ethereum earlier, but this isn’t convincing when there was strong public outcry against timing games early on that has since turned into acceptance of this new reality to be designed around.
- MEV rewards are significant – we’re already talking about billions of dollars in MEV payments here, not pennies under the couch cushion. Even making “just a few percent more” on this is a huge sum of money.
- Even if you don’t believe that stakers are sufficiently yield sensitive on the margin, the actual operators are running businesses and that goes straight to their bottom lines.
- It’s easier for Solana to rely on altruistic large stakeholders (e.g., the foundation and large investors) earlier on in its lifecycle, but that’s not sustainable as any network decentralizes further.

You can maybe argue this in certain circumstances but it doesn’t generalize when they literally do this on Ethereum today
— Jon Charbonneau (@jon_charb) June 9, 2024
I clearly think there’s a huge amount of value in the direction that both Solana and Ethereum are taking. If nothing else, we’ll get to see it all play out in practice. Strategically, I also think it makes sense for Ethereum to lean into what makes it different here. Maximize decentralization as a means to achieve censorship resistance under adversarial circumstances. Ethereum has made a lot of sacrifices to keep an incredibly decentralized protocol because that’s a necessity for the long game. It has unmatched client diversity, network ownership distribution, ecosystem stakeholders, operator decentralization, and more. If (and likely when) Solana faces serious censorship pressure in the future, it will become increasingly apparent why Ethereum has made the decisions it has.
Preconf.wtf just happened at Zuberlin last week, and perhaps unsurprisingly everyone was talking about preconfs and based rollups. And that was all really cool. But I personally found Vitalik’s talk on one-bit-per-attester inclusion lists and Barnabé’s talk on Overload the Execution Proposer instead (From MEV-Boost to ePBS to APS) to be the most important to Ethereum’s future.

Source: Barnabé Monnot, From MEV-Boost to ePBS to APS
The preconf and based rollup conversations have started to gain momentum very recently, and I’m definitely still on the more cautious side. Vitalik famously set out the below Endgame:
However, we’ve moved pretty deep into the “centralized production” without yet implementing the stronger anti-censorship protections like inclusion lists. Basically Ethereum is half in the bottom row of this picture below. (I say half because censorship isn’t actually black and white, and Ethereum only has “weak censorship”, i.e., most but not all blocks are censored, so you may just wait a little bit, but then you’ll be included):
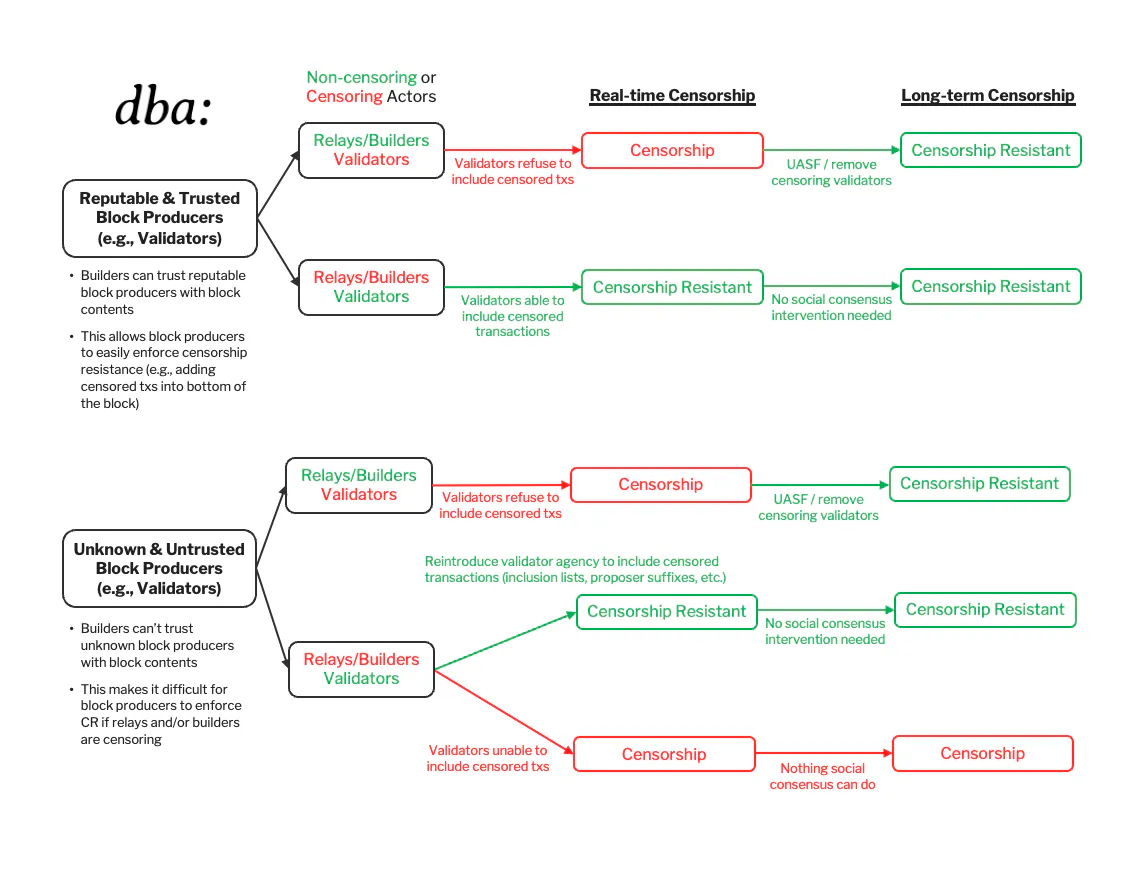
Source: Proof of Governance
Empirically, the Ethereum L1 MEV supply chain currently real-time censors more blocks than any of these L2s with centralized sequencers.

L2s can already get the L1’s eventual CR (which is very good still) without being based. Based preconfs don’t get the real-time security of the Ethereum protocol, they get the real-time security of the small handful of relatively centralized infrastructure providers around it. For better real-time CR, the best option is likely outsourcing sequencing to some type of decentralized sequencer running a simple BFT consensus. This will be far more robust than centralizing many chains into a currently relatively centralized bottleneck. This situation may improve with changes like execution auctions and inclusion lists, but that’s not exactly right around the corner.
With all of this considered, it’s not clear to me that expanding the reliance upon Ethereum L1’s MEV infrastructure then entrenching it for L2’s is a great idea at this stage when there’s a handful of people who build and relay all the Ethereum blocks, most of Ethereum’s censorship-free blocks today rely on a single builder (Titan), and none of the CR tools have been implemented in protocol yet. This feels aggressively accelerationist at a fragile spot. Ethereum should certainly be working to improve the UX of L2s, but not at the expense of all the underlying properties we wanted in the first place.

Conclusion
We’re all building the same thing.
Well, sort of. Obviously these things aren’t all literally the same exact thing. There will always be practical differences between these systems. However, the overarching mega-trend in crypto is clear that we’re all converging on increasingly similar architectures.
The nuanced technical differences between them can in practice have meaningful implications for where they end up, and we can’t underestimate how big of a role the path dependence in these systems plays even as they converge towards similar endgames.
Also, it’s pretty goddamn impossible to reason about some of this stuff. As Vitalik put it:
“One note of caution I have for APS is that I think from a purely technical perspective, I actually think it’s pretty light and we’re totally able to pull it off with quite little chance of technical error… but from an economic perspective there’s a lot more opportunity for things to go wrong…
Like EIP-1559 we were able to figure out with theory. We went to some lovely economics conferences and learned about the perils of first price auctions and how they suck, and figured out that second price auctions are not credible, and then discovered hey let’s use a mechanism that’s localized fixed price within each block, and we were able to do a lot with microeconomics.
But APS is not like that right. And the question of is APS going to lead to Citadel or Jane Street or Justin Sun or whoever producing 1% of all the Ethereum blocks or 99% is like very very difficult, probably impossible to figure out from first principles.
And so the thing that I want to see at this point is live experimentation… For me personally, the delta between today and me feeling like really deeply comfortable with APS is basically APS running successfully on an Ethereum L2 that has a medium amount of value, activity, community, and actual contention happening and that lasting for a year, possibly longer for a year, and us actually being able to see some live consequences.”
So yea, I don’t know what’s gonna happen either. We’ll just have to wait and see. In any case, while we all converge to whatever this endgame is, we’ve got a lot more in common than not, so let’s make sure to please…
Stop gaslighting each other https://t.co/5HZ9sDVQbU
— Josh (@Jskybowen) May 21, 2024
Disclaimer: The views expressed in this post are solely those of the author in their individual capacity and are not the views of DBA Crypto, LLC or its affiliates (together with its affiliates, “DBA”).
This content is provided for informational purposes only, and should not be relied upon as the basis for an investment decision, and is not, and should not be assumed to be, complete. The contents herein are not to be construed as legal, business, or tax advice. References to any securities or digital assets are for illustrative purposes only, and do not constitute an investment recommendation or offer to provide investment advisory services. This post does not constitute investment advice or an offer to sell or a solicitation of an offer to purchase any limited partner interests in any investment vehicle managed by DBA.
Certain information contained within has been obtained from third-party sources. While taken from sources believed to be reliable, DBA makes no representations about the accuracy of the information.
DBA is an investor in ETH, SOL, MATIC, Monad, and Astria. The author of this report has material personal investments in stETH, ETH, SOL, TIA, EigenLayer, and Sovereign Labs.